
Introduction
Change Data Capture (CDC) is a software design pattern that tracks row-level changes in a database — inserts, updates, and deletes — and streams those changes in near real-time to downstream consumers. Rather than polling tables or running batch jobs, CDC provides a low-latency, event-driven mechanism for propagating data changes across systems.
The Polling Problem : A pipeline polling every 5 minutes introduces up to 5 minutes of latency — and completely misses any row inserted and deleted between polls. CDC eliminates both issues, providing sub-second latency with a complete audit trail.
If you are still building data pipelines around scheduled batch jobs and timestamp-based polling, you are leaving real-time capability — and data fidelity — on the table. The Debezium + Kafka + Apache Hop stack gives you a production-grade CDC pipeline that is battle-tested, open-source, and surprisingly approachable once you understand the moving parts.
Core Concepts
What is Change Data Capture?
Traditional ETL pipelines extract full or incremental snapshots of data from source systems on a scheduled basis. This approach introduces latency (minutes to hours), imposes load on source databases, and misses intermediate state changes between polling intervals.
CDC solves this by reading the database’s write-ahead log (WAL) or transaction log — the same mechanism databases use for internal recovery — and converting every committed transaction into a structured event. This means:
- Every row-level change (INSERT, UPDATE, DELETE) is captured immediately after commit
- The source database experiences minimal additional load
- Intermediate states between poll intervals are preserved
- Schema changes (DDL events) can also be captured
The Result : Sub-second latency from source commit to downstream consumer. Zero missed deletes. Minimal load on the source database. A complete, ordered, timestamped audit trail of every change — out of the box.
Meet the Stack
This guide covers the end-to-end architecture and implementation of a CDC pipeline using three open-source tools:
Debezium — The CDC Engine
Debezium is an open-source CDC platform built on top of Kafka Connect. It connects to your database, reads the transaction log, and publishes every change as a structured JSON event to a Kafka topic — one topic per table, automatically.
It supports PostgreSQL, MySQL, SQL Server, Oracle, and more. No triggers. No shadow tables. Just direct log reading with minimal overhead.
Apache Kafka — The Event Streaming
Kafka is the backbone. It receives Debezium’s events and holds them durably — replayed, partitioned by primary key, and retained as long as you need. Downstream consumers can read at their own pace without affecting the source.
Think of it as a distributed, ordered, infinitely replayable changelog for your entire data ecosystem
Apache Hop — The Transformation Layer
Apache Hop is a visual data orchestration platform. It consumes Kafka topics, parses the Debezium event envelope, routes events by operation type, transforms them, and loads them to any target—data warehouse, data lake, or downstream service.
Its visual pipeline designer makes CDC logic transparent and maintainable — no black-box ETL scripts.
ClickHouse — The Analytical Target
ClickHouse is a column-oriented OLAP database designed for high-throughput ingestion and millisecond analytical queries at scale. It is where the CDC events ultimately land — continuously updated from the source via Debezium and Hop and available for real-time reporting, dashboards, and aggregations. We cover ClickHouse in depth in its own section below.
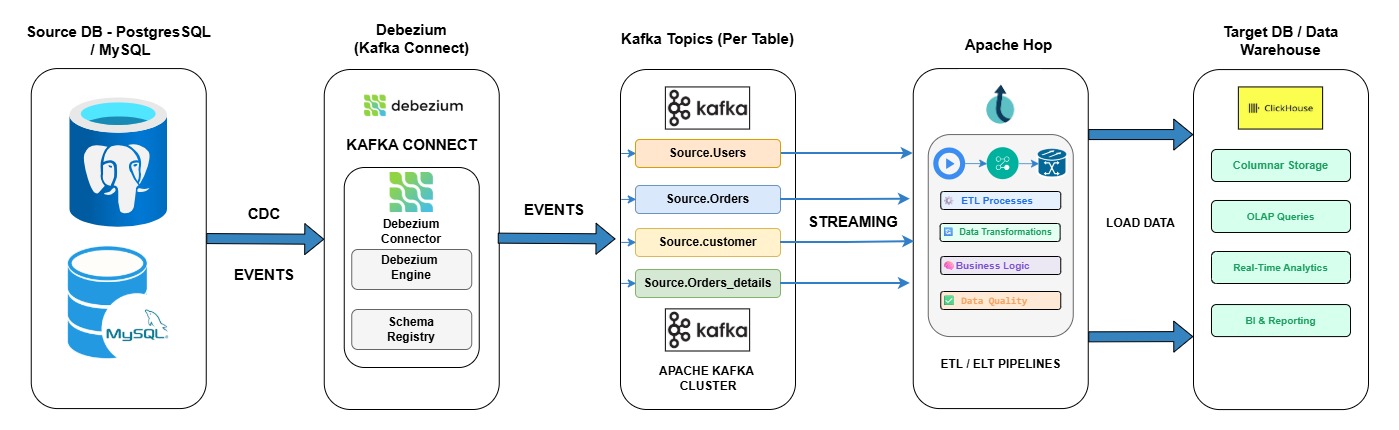
Architecture Overview
The reference architecture for a Debezium + Kafka + Hop + ClickHouse DB CDC pipeline consists of four logical layers:
Layer | Component | Role |
1 | Source Database | PostgreSQL / MySQL / MongoDB — emits a transaction log on every commit |
2 | Debezium (Kafka Connect) | Reads the log, converts changes to JSON events, publishes to Kafka |
3 | Apache Kafka | Stores events durably, partitioned by row PK, retained for replay |
4 | Apache Hop | Consumes events, parses & routes by operation type, loads to target |
5 | ClickHouse DB | It has Columnar Storage, OLAP Queries, Real-Time Analytics & BI tools |
Architecture Flow
Source DB [PostgreSQL/MySQL] → Debezium / Kafka Connect → Kafka Topics (per table) → Apache Hop → ClickHouse
The Debezium CDC Engine
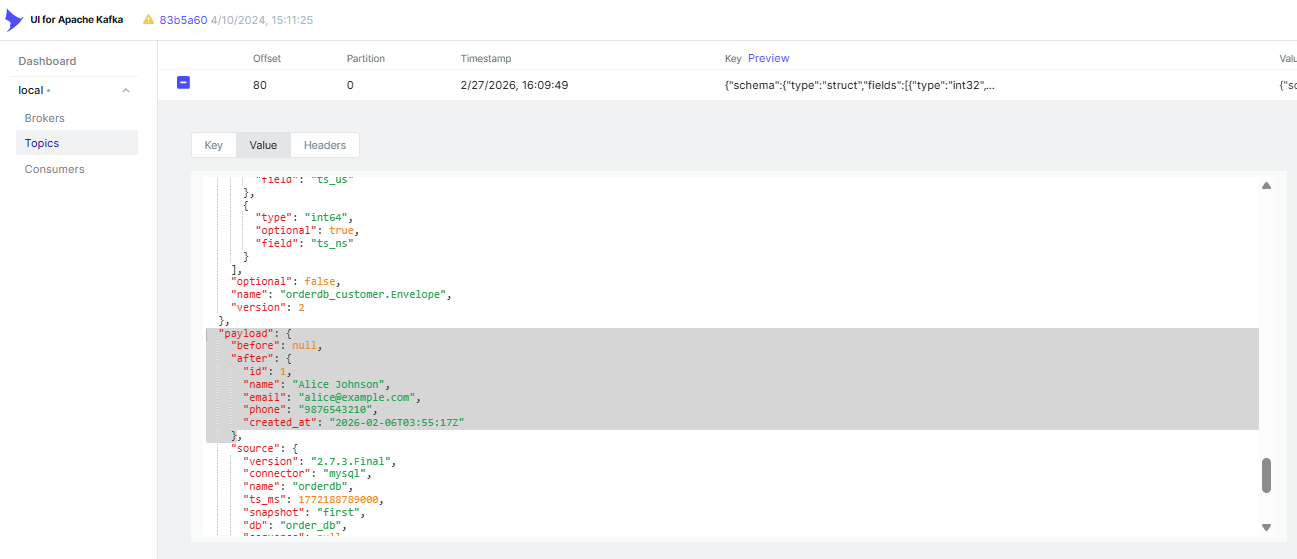
Every Debezium event carries a full before/after snapshot of the row as a JSON message to a Kafka topic. Each message contains a structured envelope with the following key fields:
- before — the row state before the change (null for INSERTs)
- after — the row state after the change (null for DELETEs)
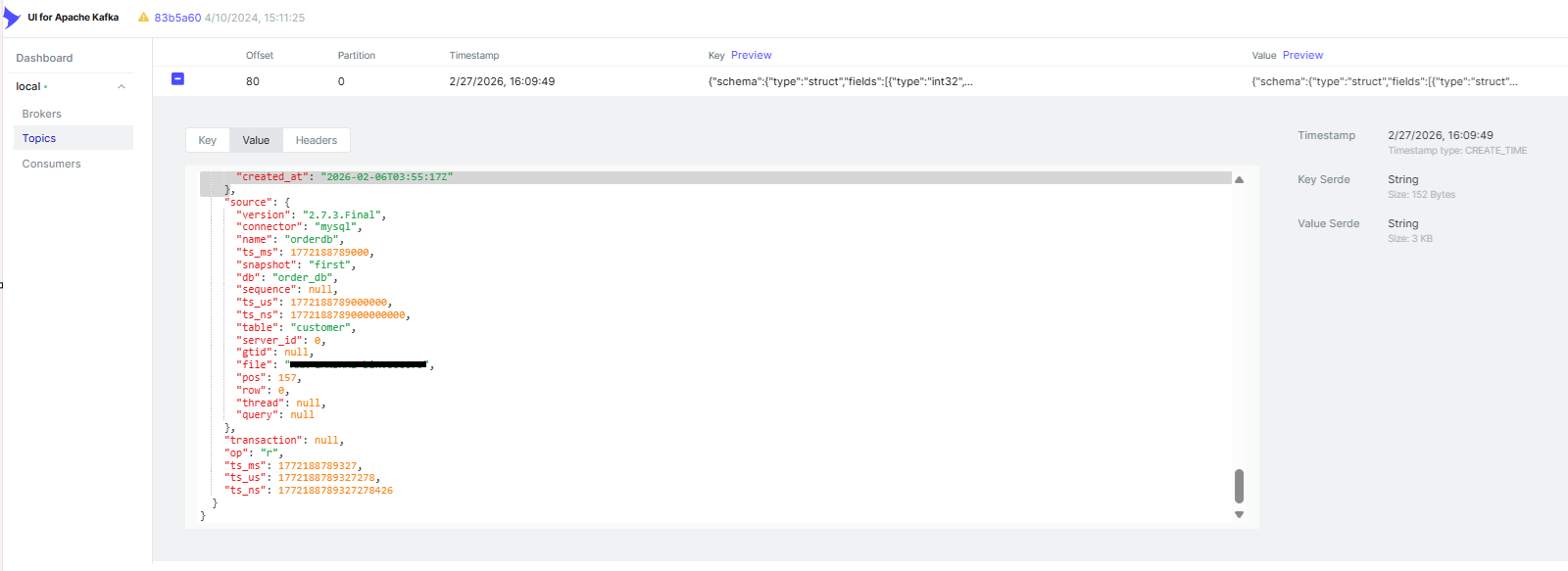
- source — metadata: connector name, database, table, transaction ID, LSN/binlog position, timestamp
- ts_ms — event timestamp in milliseconds
op—operation type: “c” = create, “u” = update, “d” = delete, “r” = initial snapshot read. Apache Hop routes each event to the correct action based on this field.
Kafka Event Streaming
By default, Debezium publishes each table’s events to a dedicated Kafka topic following this convention:
Offset Tracking & Exactly-Once Guarantees
Debezium stores its read position (LSN for PostgreSQL, binlog coordinates for MySQL) in a dedicated Kafka topic called the offset storage topic. This provides:
- Crash recovery—the connector resumes from the last committed offset after restart
- Exactly-once delivery when combined with Kafka transactions and idempotent producers
Reprocessing capability — offsets can be manually reset to replay historical changes
Getting Started: Key Setup Steps
Prerequisites
- Apache Kafka 3.x with Kafka Connect (distributed or standalone mode)
- Source database with CDC/replication enabled (see per-database instructions below)
- Debezium connector plugin JARs on the Kafka Connect plugin path
- Docker – Local Setup
Seeing It in Action
The quickest way to get the full stack running locally is Docker Compose—a single command brings up Kafka, Zookeeper, Kafka Connect (with Debezium), Kafka UI, and MySQL/PostgreSQL source databases together. No manual installation needed.
Set up the stack
Define all five services in a docker-compose.yml and start them with
Once healthy, the services are available at: Kafka on :9092, Kafka Connect REST API on :8083, and Kafka UI on :8080.

Register the Debezium Connector
With the stack running, register a connector via the Kafka Connect REST API. One POST request is all it takes — Debezium takes an initial snapshot of your tables and then switches to real-time streaming automatically.

Browse Live Events in Kafka UI
Open localhost:8080 in your browser. Kafka UI gives you a real-time view of everything flowing through the pipeline — topics, messages, consumer group lag, and connector health — without touching the command line.
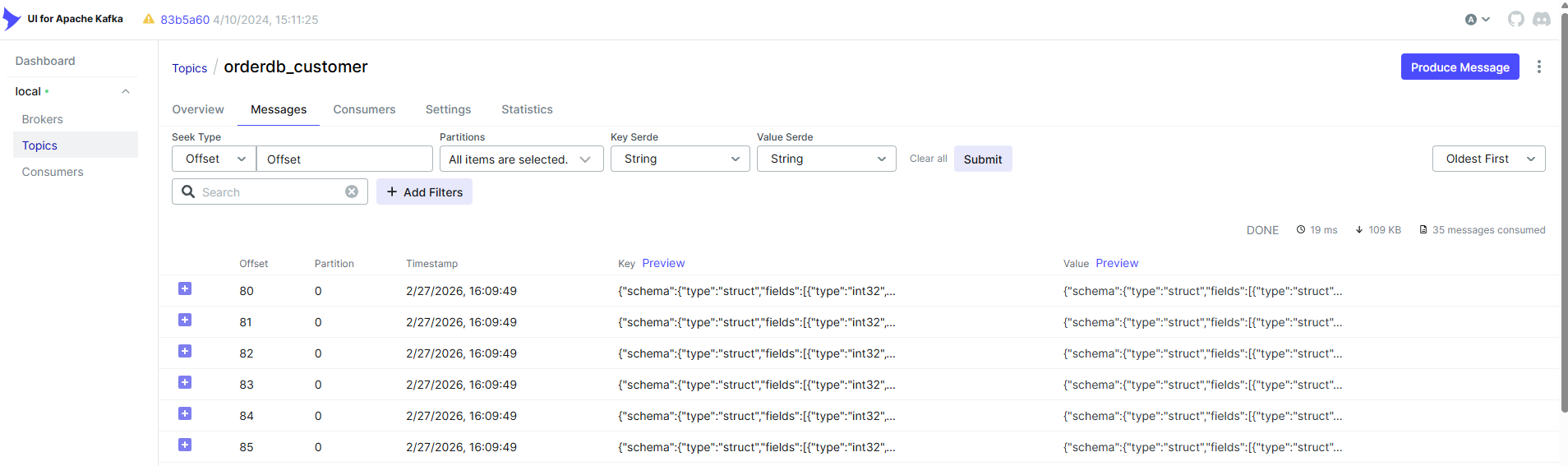
Under Topics, you’ll see a dedicated topic for each captured table (e.g.orderdb.customers). Click into any topic and open the Messages tab to inspect the full Debezium envelope — before, after, op, and source metadata — for every change in real time.
The Kafka Connect section of Kafka UI also lets you view, pause, restart, and monitor connectors visually — no REST API calls needed for day-to-day management.
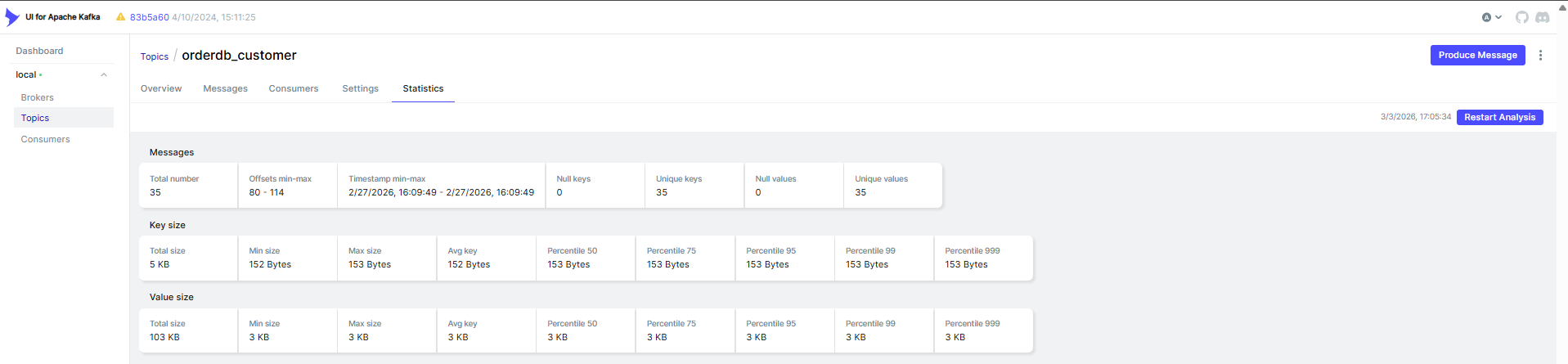
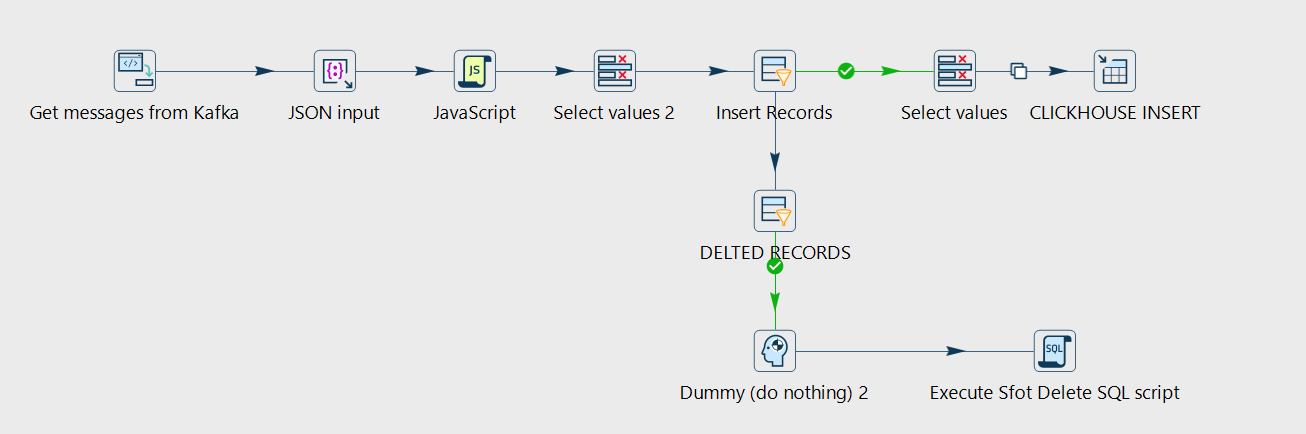
Consuming CDC Events with Apache Hop
Apache Hop is a visual data orchestration platform where you build pipelines as graphs — drag steps onto a canvas, connect them, and configure each one.
It has a native Kafka Consumer step, which makes it well-suited for consuming Kafka topics, parsing the event envelope, and routing events to their targets.
The visual approach makes CDC pipelines more maintainable than hand-rolled consumer code, and Hop’s error-handling steps make it straightforward to implement dead-letter queue patterns for malformed events.
Key Hop concepts relevant to CDC pipelines are the following:
Hop Concept | Description |
Pipeline | A data flow graph — transforms data row by row using connected steps |
Workflow | An orchestration graph — sequences actions, calls pipelines, handles errors |
Metadata | Reusable connection definitions (Kafka, JDBC, etc.) stored as XML or in a metadata store |
Pipeline Flow
Get Message from Kafka Consumer → Parse JSON → FILTER → Insert / Upsert / Soft-Delete → Target (CLICKHOUSE)
Why ClickHouse as the Target Database
ClickHouse is an open-source column-oriented OLAP database originally developed at Yandex and now maintained by ClickHouse Inc. It is purpose-built for one thing: ingesting large volumes of data continuously and answering complex analytical queries across billions of rows in milliseconds.
Unlike row-oriented databases like PostgreSQL or MySQL — which store each record as a contiguous unit on disk — ClickHouse stores each column independently. This means analytical queries that touch only a few columns scan dramatically less data. Compression ratios are also far higher because similar values sit together. The result is query performance that would be impossible on a transactional database of the same scale.
Why ClickHouse is the right CDC target for analytics: Debezium keeps ClickHouse continuously updated with sub-second latency while ClickHouse handles all analytical load. You get real-time reporting dashboards and aggregations without ever running a single analytical query against your production OLTP database.
CDC vs. Polling: Comparison
| Capability | CDC (Debezium) | Query Polling |
| Latency | Sub-second | Minutes to hours |
| Captures deletes | ✓ Yes | ✗ No |
| Intermediate states | ✓ Preserved | ✗ Lost |
| Source DB load | Very low | Moderate to high |
| Requires table schema change | ✓ No | ✗ Needs updated_at column |
| Event replay | ✓ Yes (Kafka retention) | ✗ No |
| Setup complexity | Moderate | Low |
When This Stack Is the Right Choice
CDC is the right tool when you need low latency, when your use case depends on capturing every change, including deletes, or when polling is adding unacceptable load to your source system. It’s particularly well-suited for:
- Real-time analytics — stream OLTP changes into ClickHouse for sub-second analytical query freshness
- Operational reporting — live dashboards over production data without touching the source DB
- Audit and compliance trails — every insert, update, and delete is captured and timestamped
- Cache and search sync — keep Redis, Elasticsearch, or other secondary stores consistent with the source
- Zero-downtime migrations — stream data continuously from the old system to the new one during cutover
Other Related Blog Posts
Check out our other Blog posts:
- Integrating Apache Hop with n8n: Axxonet’s Blueprint for Scalable, Automation‑Driven Data Pipelines
- SQL Server Integration Service vs Apache Hop – Execution, Cloud Strategy, and the Microsoft Fabric Question (Part 2)
- SQL Server Integration Service vs Apache Hop – How ETL Tools have evolved and where Modern Tools Fit In (Part 1 of 2)
- Apache Hop Meets GitLab: CICD Automation with GitLab
- Simpler alternative to Kubernetes – Docker Swarm with Swarmpit
- Why choose Apache Druid over Snowflake
- Apache Druid Integration with Apache Superset
- Streamlining Apache HOP Workflow Management with Apache Airflow
- Comparison of and migrating from Pentaho Data Integration PDI/ Kettle to Apache HOP
Reach out to us at analytics@axxonet.net or submit your details via our contact form.




