Introduction
In our previous blog, Apache Druid Integration with Apache Superset we talked about Apache Druid’s integration with Apache Superset. In case you have missed it, it is recommended you read it before continuing the Apache Druid blog series. In the Exploring Apache Druid: A High-Performance Real-Time Analytics Database blog post, we have talked about Apache Druid in more detail.
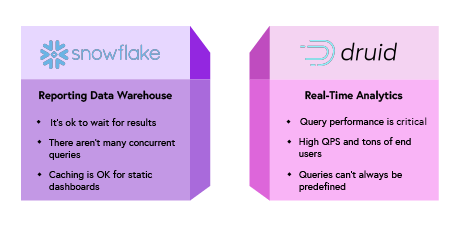
In this blog, we talk about the advantages of Druid over Snowflake. Apache Druid and Snowflake are both high-performance databases, but they serve different use cases, with Druid excelling in real-time analytics and Snowflake in traditional data warehousing.
Snowflake
Snowflake is a cloud-based data platform and data warehouse service that has gained significant popularity due to its performance, scalability, and ease of use. It is built from the ground up for the cloud and offers a unified platform for data warehousing, data lakes, data engineering, data science, and data application development
Apache Druid
Apache Druid is a high-performance, distributed real-time analytics database designed to handle fast, interactive queries on large-scale datasets, especially those with a time component. It is widely used for powering business intelligence (BI) dashboards, real-time monitoring systems, and exploratory data analytics.
Here are the advantages of Apache Druid over Snowflake, particularly in real-time, time-series, and low-latency analytics:
(a) Real-Time Data Ingestion
- Apache Druid: Druid is designed for real-time data ingestion, making it ideal for applications where data needs to be available for querying as soon as it’s ingested. It can ingest data streams from sources like Apache Kafka or Amazon Kinesis and make the data immediately queryable.
- Snowflake: Snowflake is primarily a batch-processing data warehouse. While Snowflake can load near real-time data using external tools or connectors, it is not built for real-time streaming data ingestion like Druid.
Advantage: Druid is superior for real-time analytics, especially for streaming data from sources like Kafka and Kinesis.
(b) Sub-Second Query Latency for Interactive Analytics
- Apache Druid: Druid is optimized for sub-second query latency, which makes it highly suitable for interactive dashboards and ad-hoc queries. Its columnar storage format and advanced indexing techniques (such as bitmap and inverted indexes) enable very fast query performance on large datasets, even in real time.
- Snowflake: Snowflake is highly performant for large-scale analytical queries, but it is designed for complex OLAP (Online Analytical Processing) queries over historical data, and query latency may be higher for low-latency, real-time analytics, particularly for streaming or fast-changing datasets.
Advantage: Druid offers better performance for low-latency, real-time queries in use cases like interactive dashboards or real-time monitoring.
(c) Time-Series Data Optimization
- Apache Druid: Druid is natively optimized for time-series data, with its architecture built around time-based partitioning and segmenting. This allows for efficient querying and storage of event-driven data (e.g., log data, clickstreams, IoT sensor data).
- Snowflake: While Snowflake can store and query time-series data, it does not have the same level of optimization for time-based queries as Druid. Snowflake is better suited for complex, multi-dimensional queries rather than the high-frequency, time-stamped event queries where Druid excels.
Advantage: Druid is more optimized for time-series analytics and use cases where data is primarily indexed and queried based on time.
(d) Streaming Data Support
- Apache Druid: Druid has native support for streaming data platforms like Kafka and Kinesis, enabling direct ingestion from these sources and offering real-time visibility into data as it streams in.
- Snowflake: Snowflake supports streaming data through tools like Snowpipe, but it works better with batch data loading or micro-batch processing. Its streaming capabilities are generally less mature and lower-performing compared to Druid’s real-time streaming ingestion.
Advantage: Druid has stronger native streaming data support and is a better fit for real-time analytics from event streams.
(e) Low-Latency Aggregations
- Apache Druid: Druid excels in performing low-latency aggregations on event data, making it ideal for use cases that require real-time metrics, summaries, and rollups. For instance, it’s widely used in monitoring, fraud detection, ad tech, and IoT, where data must be aggregated and queried in near real-time.
- Snowflake: While Snowflake can aggregate data, it is more optimized for batch-mode processing, where queries are run over large datasets. Performing continuous, real-time aggregations would require external tools and more complex architectures.
Advantage: Druid is better suited for real-time aggregations and rollups on streaming or event-driven data.
(f) High Cardinality Data Handling
- Apache Druid: Druid’s advanced indexing techniques, like bitmap indexes and sketches (e.g., HyperLogLog), allow it to efficiently handle high-cardinality data (i.e., data with many unique values). This is important for applications like ad tech where unique user IDs, URLs, or click events are frequent.
- Snowflake: Snowflake performs well with high-cardinality data in large-scale analytical queries, but its query execution model is generally more suited to aggregated batch processing rather than fast, high-cardinality lookups and filtering in real time.
Advantage: Druid has better indexing for real-time queries on high-cardinality datasets.
(g) Real-Time Analytics for Operational Use Cases
- Apache Druid: Druid was built to serve operational analytics use cases where real-time visibility into systems, customers, or events is critical. Its ability to handle fast-changing data and return instant insights makes it ideal for powering monitoring dashboards, business intelligence tools, or real-time decision-making systems.
- Snowflake: Snowflake is an excellent data warehouse for historical and batch-oriented analytics but is not optimized for operational or real-time analytics where immediate insights from freshly ingested data are needed.
Advantage: Druid is better suited for operational analytics and real-time, event-driven systems.
(h) Cost-Effectiveness for Real-Time Workloads
- Apache Druid: Druid’s open-source nature means there are no licensing fees, and you only pay for the infrastructure it runs on (if you use a managed service or deploy it on the cloud). For organizations with significant real-time analytics workloads, Druid can be more cost-effective than cloud-based data warehouses, which charge based on storage and query execution.
- Snowflake: Snowflake’s pricing is based on compute and storage usage, with charges for data loading, querying, and storage. For continuous, high-frequency querying (such as real-time dashboards), these costs can add up quickly.
Advantage: Druid can be more cost-effective for real-time analytics, especially in high-query environments with constant data ingestion.
(i) Schema Flexibility and Semi-Structured Data Handling
- Apache Druid: Druid supports schema-on-read and is highly flexible in terms of handling semi-structured data such as JSON or log formats. This flexibility is particularly useful for use cases where the schema may evolve over time or when working with less structured data types.
- Snowflake: Snowflake also handles semi-structured data like JSON, but it requires more structured schema management compared to Druid’s flexible schema handling, which makes Druid more adaptable to changes in data format or structure.
Advantage: Druid offers greater schema flexibility for semi-structured data and evolving datasets.
(j) Open-Source and Vendor Independence
- Apache Druid: Druid is open-source, which gives users full control over deployment, management, and scaling without being locked into a specific vendor. This makes it a good choice for organizations that want to avoid vendor lock-in and have the flexibility to self-manage or choose different cloud providers.
- Snowflake: Snowflake is a proprietary, cloud-based data warehouse. While Snowflake offers excellent cloud capabilities, users are tied to Snowflake’s platform and pricing model, which may not be ideal for organizations preferring more control or customization in their infrastructure.
Advantage: Druid provides more freedom and control as an open-source platform, allowing for vendor independence.
When to Choose Apache Druid over Snowflake
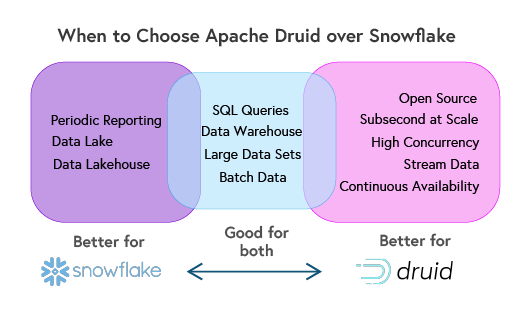
- Real-Time Streaming Analytics: If your use case involves high-frequency event data or real-time streaming analytics (e.g., user behavior tracking, IoT sensor data, or monitoring dashboards), Druid is a better fit.
- Interactive, Low-Latency Queries: For interactive dashboards requiring fast response times, especially with frequently updated data, Druid’s sub-second query performance is a significant advantage.
- Time-Series and Event-Driven Data: Druid’s architecture is designed for time-series data, making it superior for analyzing log data, time-stamped events, and similar data.
- Operational Analytics: Druid excels in operational analytics where real-time data ingestion and low-latency insights are needed for decision-making.
- Cost-Effective Real-Time Workloads: For continuous real-time querying and analysis, Druid’s cost structure may be more affordable compared to Snowflake’s compute-based pricing.
Data Ingestion, Data Processing, and Data Querying
Apache Druid
Data Ingestion and Data Processing
Apache Druid is a high-performance real-time analytics database designed for fast querying of large datasets. One common use case is ingesting a CSV file into Druid to enable interactive analysis. In this guide, we will walk through each step to upload a CSV file to Apache Druid, covering both the Druid Console and the ingestion configuration details.
Note: We have used the default configuration settings that come with the trial edition of Apache Druid and Snowflake for this exercise. Results may vary depending on the configuration of the applications.
Prerequisites:
(a) Ensure your CSV file is:
- Properly formatted, with headers in the first row.
- Clean of inconsistencies (e.g., missing data or malformed values).
- Stored locally or accessible via a URL if uploading from a remote location.
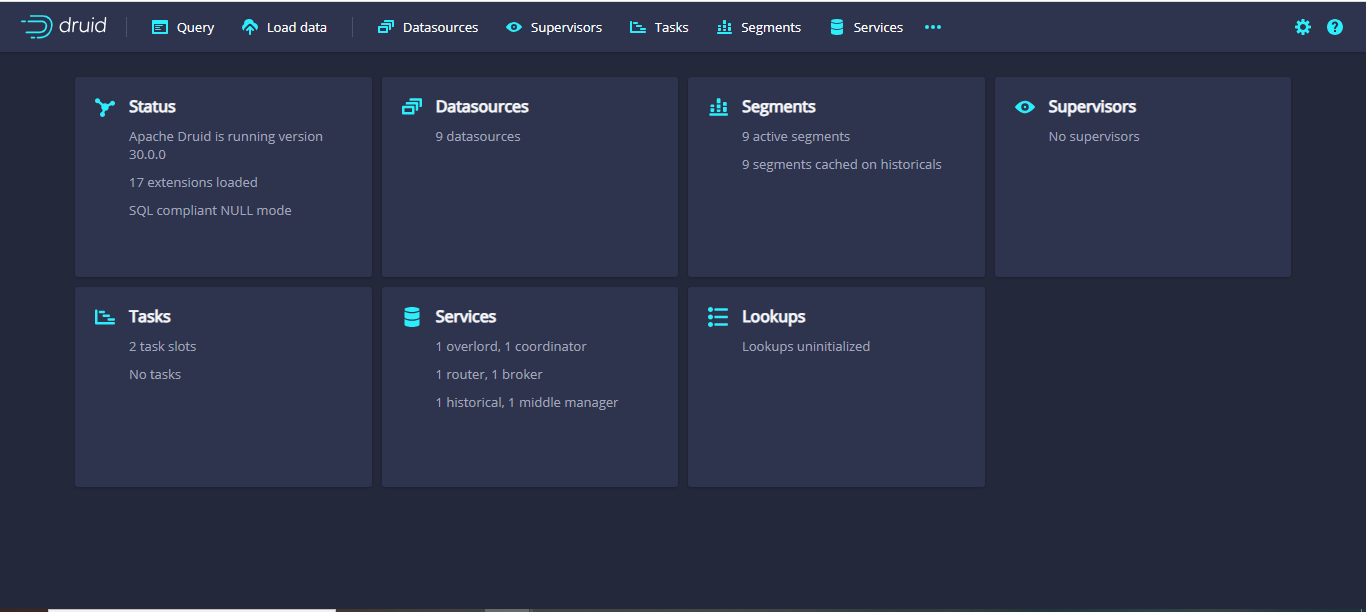
(b) Launch the Apache Druid Console.
(c) Start your Apache Druid cluster if it is not already running.
(d) Open the Druid Console by navigating to its URL (default: http://localhost:8888).
(e) Load Data: Select the Datasources Grid.
Create a New Data Ingestion Task
(a) Navigate to the Ingestion Section:
- In the Druid Console, click on Data in the top navigation bar.
- Select Load data to start a new ingestion task.
(b) Choose the Data Source:
- Select Local disk if the CSV file is on the same server as the Druid cluster.
- Select HTTP(s) if the file is accessible via a URL.
- Choose Amazon S3, Google Cloud Storage, or other options if the file is stored in a cloud storage service.
(c) Upload or Specify the File Path:
- For local ingestion: Provide the absolute path to the CSV file.
- For HTTP ingestion: Enter the file’s URL.
(d) Start a New Batch Spec: We are using a new file for processing.

(e) Connect and parse raw data: Select Local Disk option.

(f) Specify the Data: Select the base directory of the file and choose the file type you are using to process.
- File Format:
- Select CSV as the file format.
- If your CSV uses a custom delimiter (e.g., ;), specify it here.
- Parse Timestamp Column:
- Druid requires a timestamp column to index the data.
- Select the column containing the timestamp (e.g., timestamp).
- Specify the timestamp format if it differs from ISO 8601 (e.g., yyyy-MM-dd HH:mm:ss).
- Preview Data:
- The console will show a preview of the parsed data.
- Ensure that all columns are correctly identified.
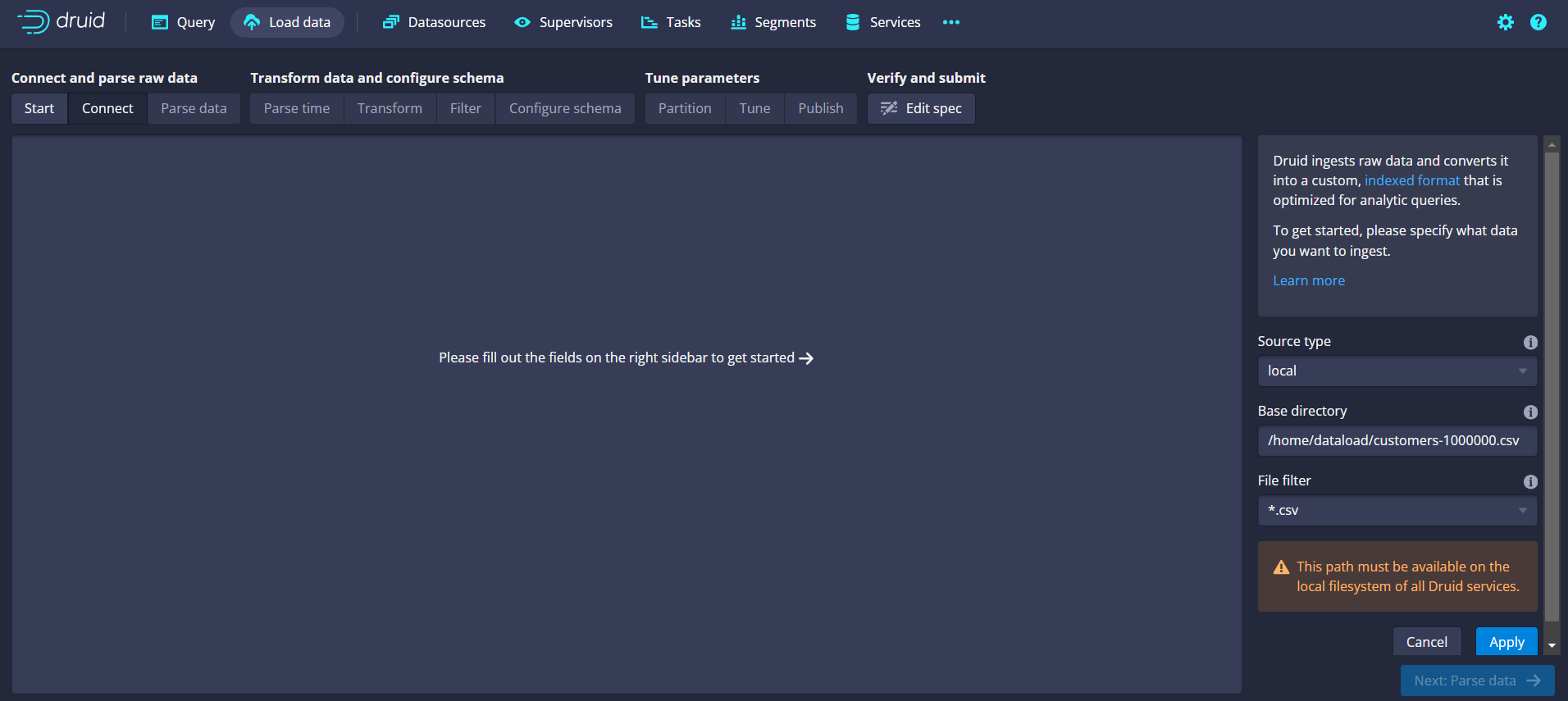
(g) Connect: Connect details.

(h) Parse Data: At this stage, you should be able to see the data in Druid to parse it.
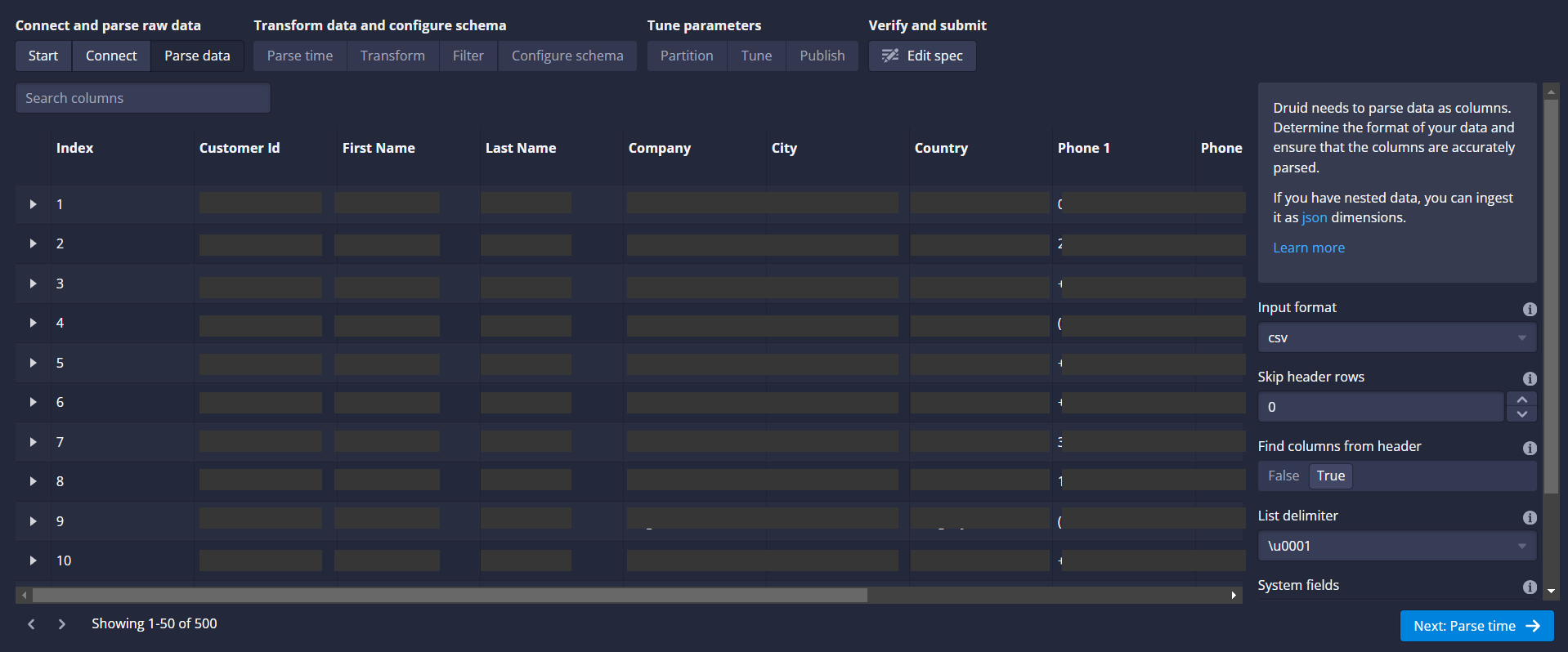
(i) Parse Time: At this stage, you should be able to see the data in Druid to parse the time details.

(j) Transform: At this stage, Druid allows you to perform some fundamental Transformations.
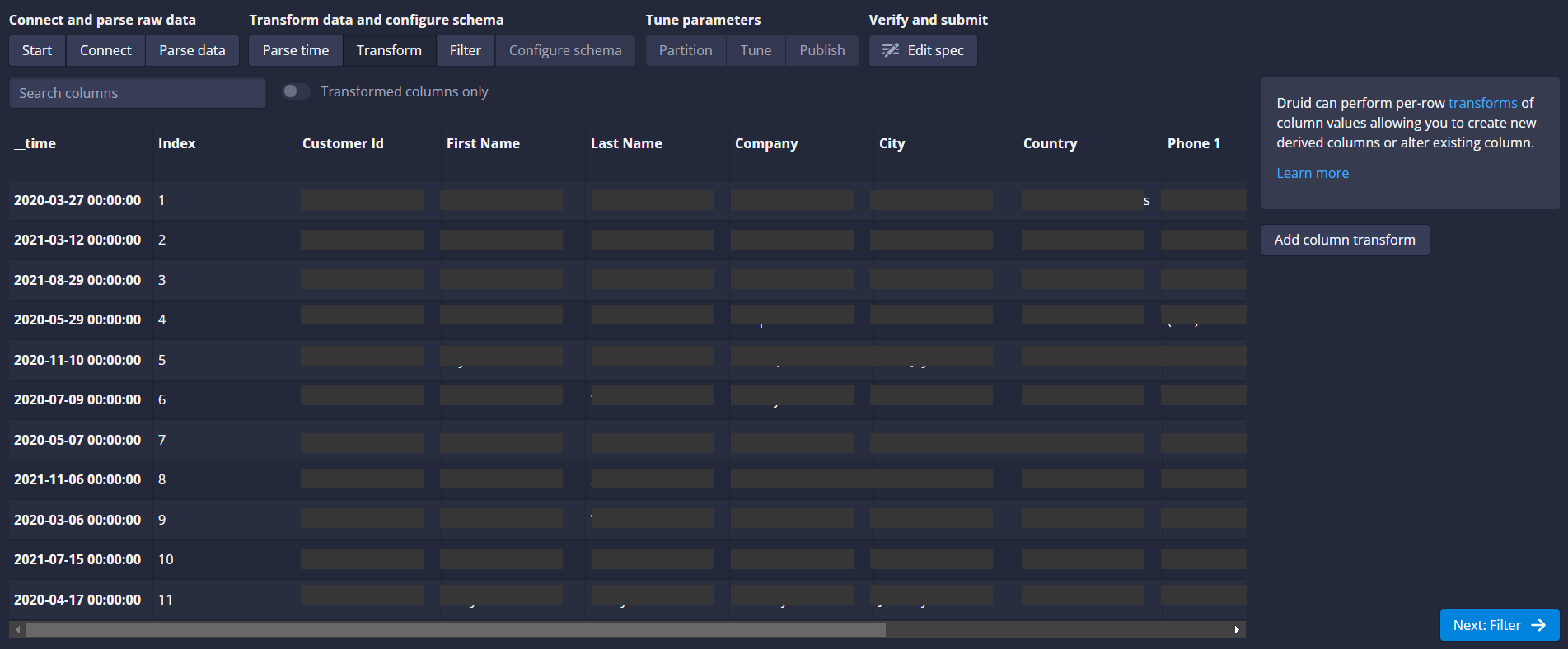
(k) Filter: At this stage, Druid allows you to apply the filter conditions to your data.

(l) Configure Schema: At this stage, we are configuring the Schema details about the file that we had uploaded to the Druid.
- Define Dimensions and Metrics:
- Dimensions are fields you want to filter or group by (e.g., category).
- Metrics are fields you want to aggregate (e.g., value).
- Primary Timestamp:
- Confirm the primary timestamp field.
- Partitioning and Indexing:
- Select a time-based partitioning scheme, such as day or hour.
- Choose indexing options like bitmap or auto-compaction if needed.
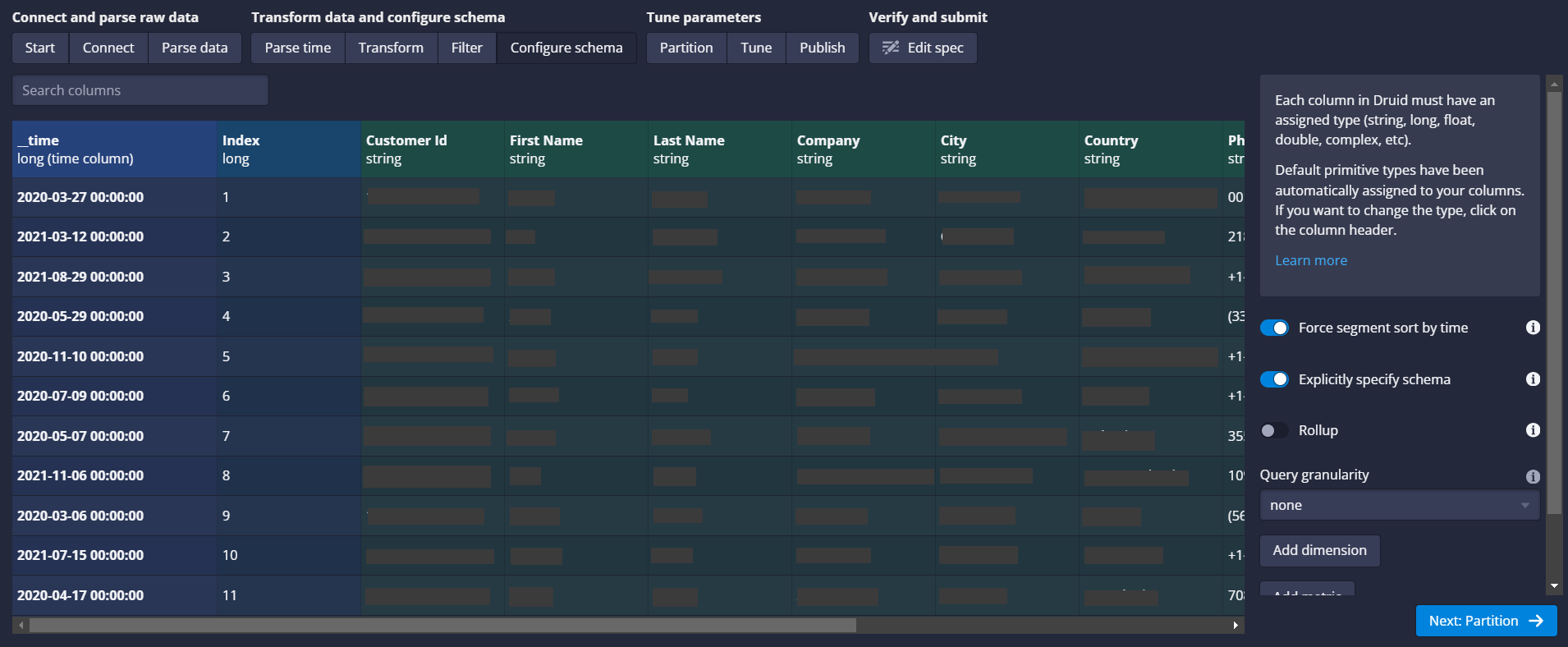
(m) Partition: At this stage, Druid allows you to configure the Date specific granularity details.

(n) Tune:
- Max Rows in Memory:
- Specify the maximum number of rows to store in memory during ingestion.
- Segment Granularity:
- Define how data is divided into segments (e.g., daily, hourly).
- Partitioning and Indexing:
- Configure the number of parallel tasks for ingestion if working with large datasets.
- Max Rows in Memory:

(o) Publish:
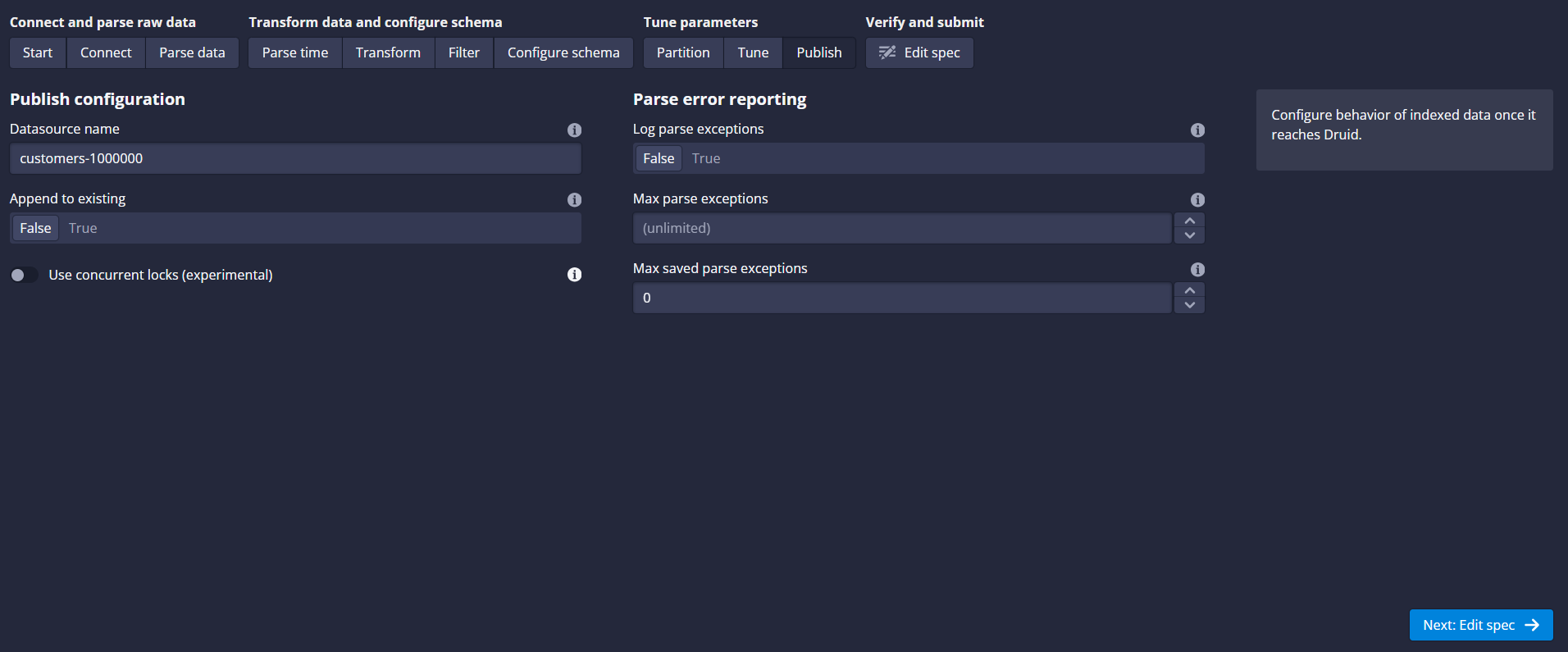
(p) Edit Spec:

(q) Submit Task:
- Generate the Ingestion Spec:
- Review the auto-generated ingestion spec JSON in the console.
- Edit the JSON manually if you need to add custom configurations.
- Submit the Task:
- Click Submit to start the ingestion process.
- Generate the Ingestion Spec:
(r) Monitor the Ingestion Process:
- Navigate to the Tasks section in the Druid Console.
- Monitor the progress of the ingestion task.
- If the task fails, review the logs for errors, such as incorrect schema definitions or file path issues.

Processing a CSV data load of 1 Million data in 33 sec.
Data Querying
Query the Ingested Data
- Navigate to the Query Tab:
- In the Druid Console, go to Query and select your new data source.
- Write and Execute Queries:
- Use Druid SQL or the native JSON query language to interact with your data.
- Navigate to the Query Tab:
Example SQL Query:
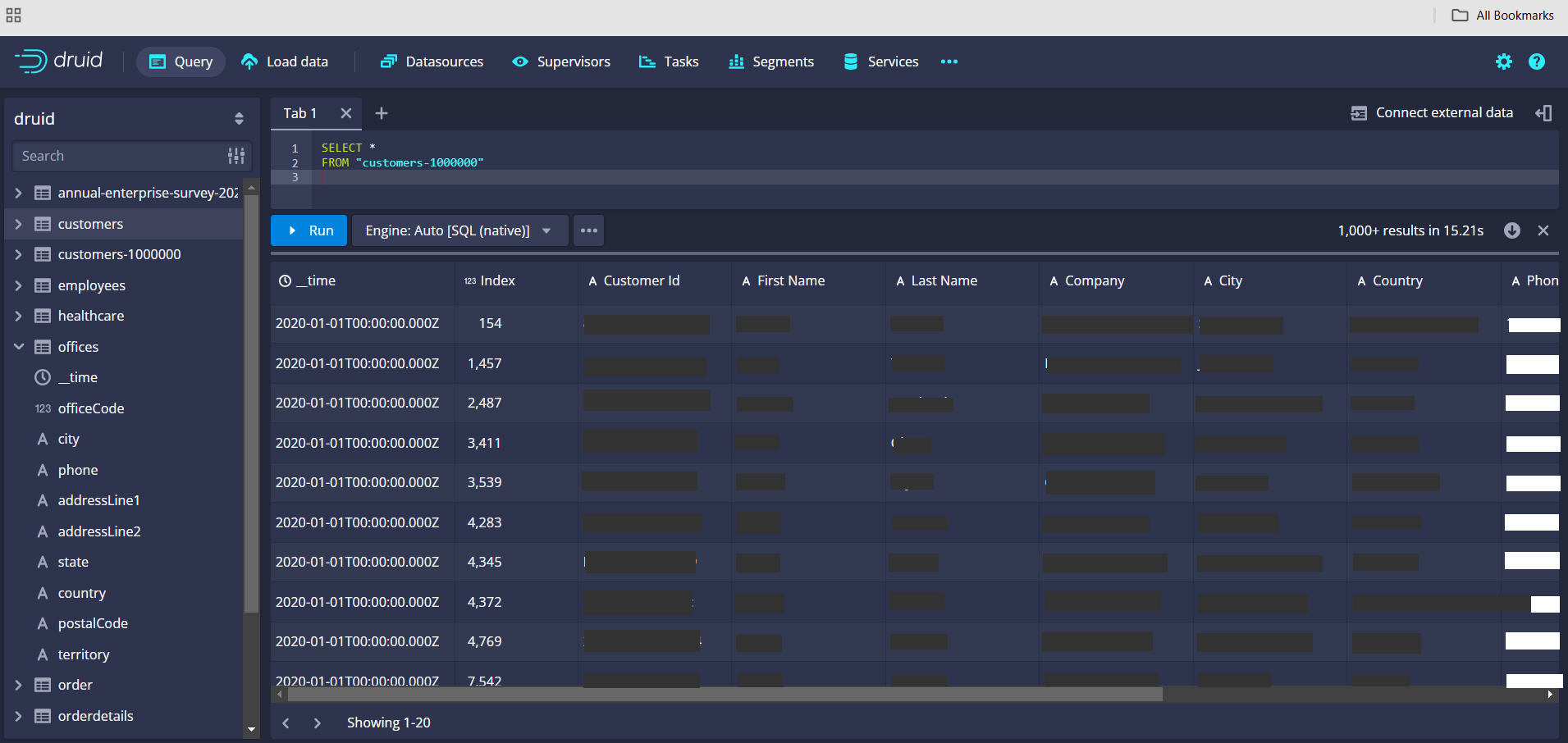
Query Performance for querying and rendering of 1 million rows is 15 ms.
- Visualize Results:
- View the query results directly in the console or connect Druid to a visualization tool like Apache Superset. In our upcoming blog we will see how to visualize this ingested data using Apache Superset. Meanwhile In our previous blog, Exploring Apache Druid: A High-Performance Real-Time Analytics Database, and Apache Druid Integration with Apache Superset we discussed Apache Druid in more detail. In case you have missed it, it is recommended that you read it before continuing the Apache Druid blog series. In this blog, we talk about integrating Apache Superset and Apache Druid.
- View the query results directly in the console or connect Druid to a visualization tool like Apache Superset. In our upcoming blog we will see how to visualize this ingested data using Apache Superset. Meanwhile In our previous blog, Exploring Apache Druid: A High-Performance Real-Time Analytics Database, and Apache Druid Integration with Apache Superset we discussed Apache Druid in more detail. In case you have missed it, it is recommended that you read it before continuing the Apache Druid blog series. In this blog, we talk about integrating Apache Superset and Apache Druid.
Uploading data sets to Apache Druid is a straightforward process, thanks to the intuitive Druid Console. By following these steps, you can ingest your data, configure schemas, and start analyzing it in no time. Whether you’re exploring business metrics, performing real-time analytics, or handling time-series data, Apache Druid provides the tools and performance needed to get insights quickly.
Snowflake
- Log in to the Snowflake application using the credentials.
2. Upload the CSV file to the Server.

3. The uploaded “customer.csv” file has 1 Million data rows and the size of the file is around 166 MB.

4. Specify the Snowflake Database.
5. Specify the Snowflake Table.
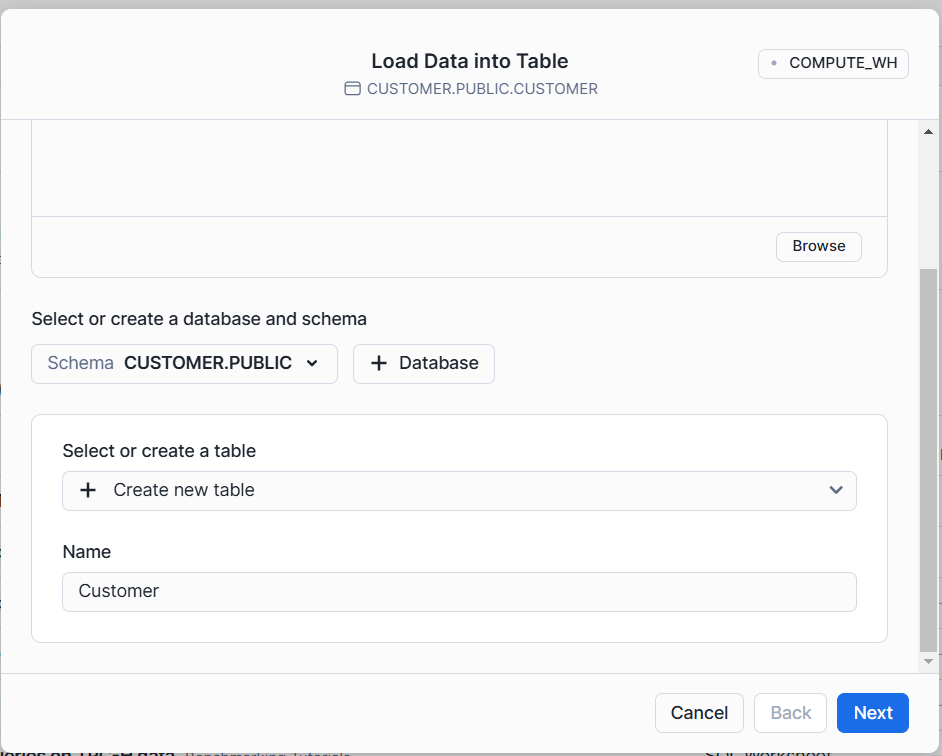
6. The CSV data is being processed into the specified Snowflake Database and table.

7. Snowflake allows us to format or edit the metadata information before loading the data into Snowflake DB. Update the details as per the data and click on the Load button.
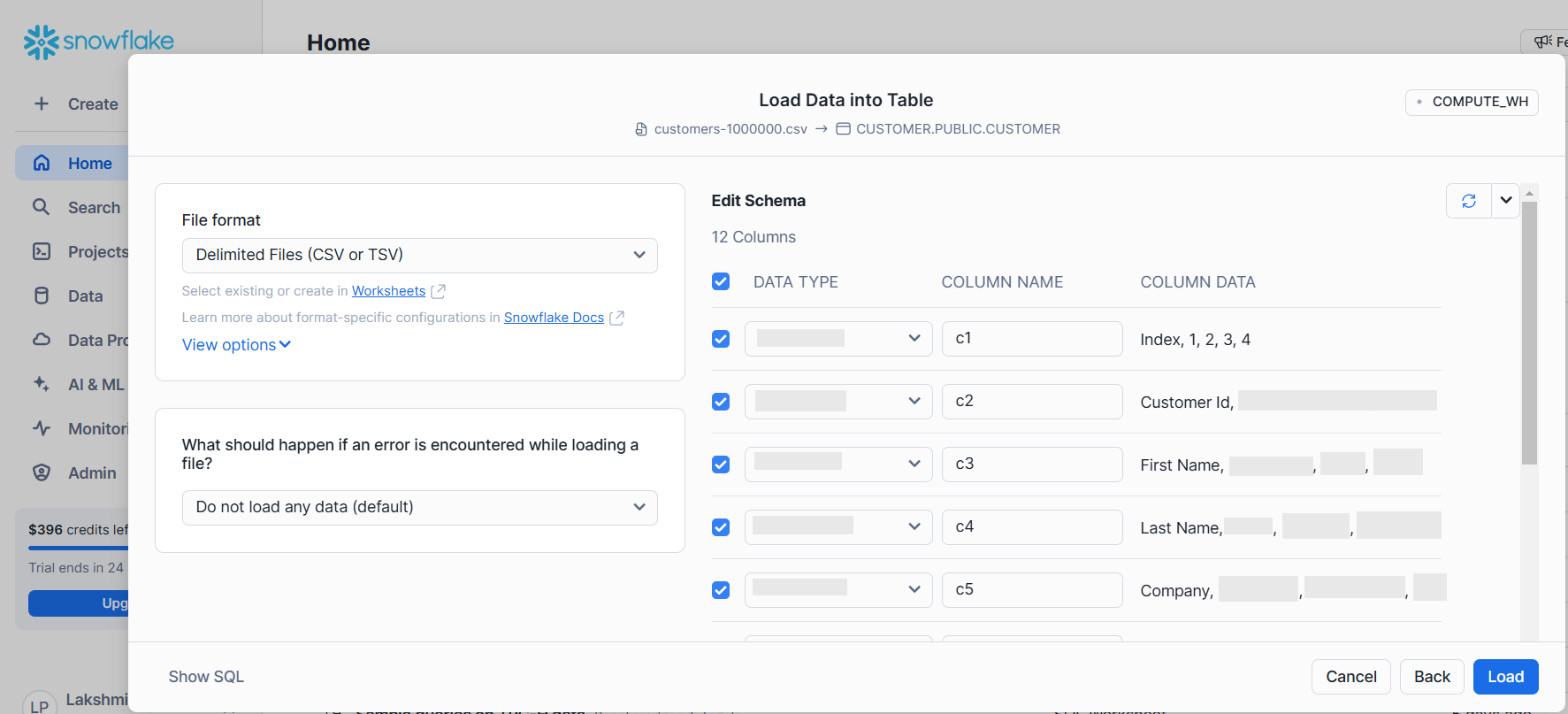

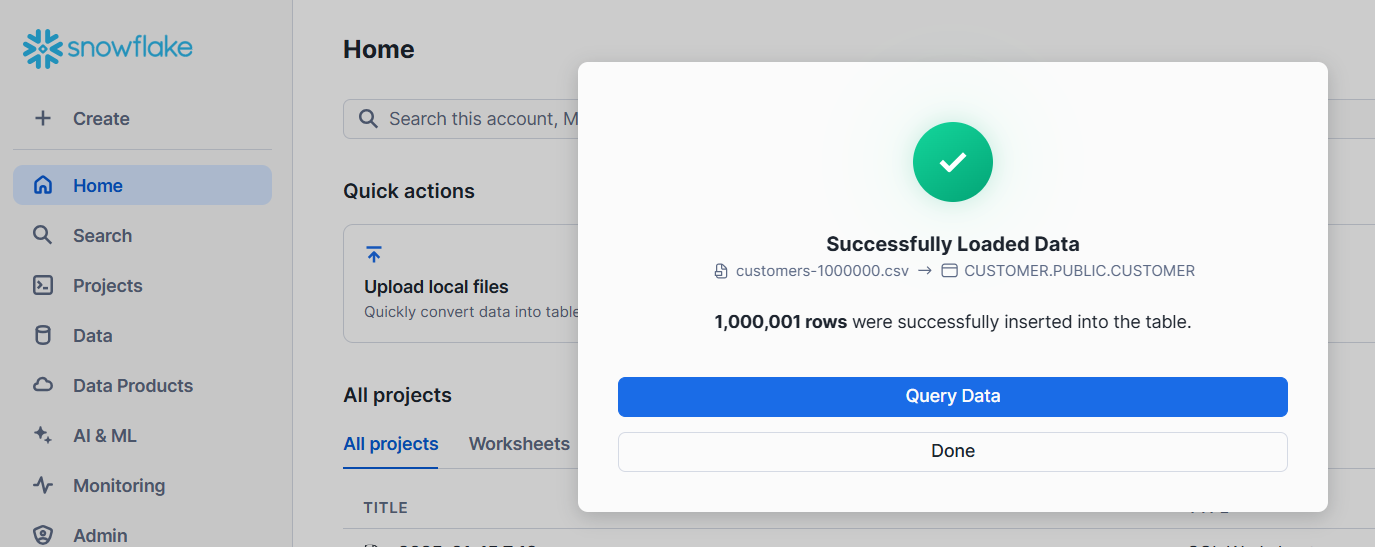
8. Snowflake successfully loaded customer data. Snowflake has taken 45 sec to process the CSV data. Snowflake has taken 12+ seconds compared to Apache Druid to load, transform, and process 1 Million records.
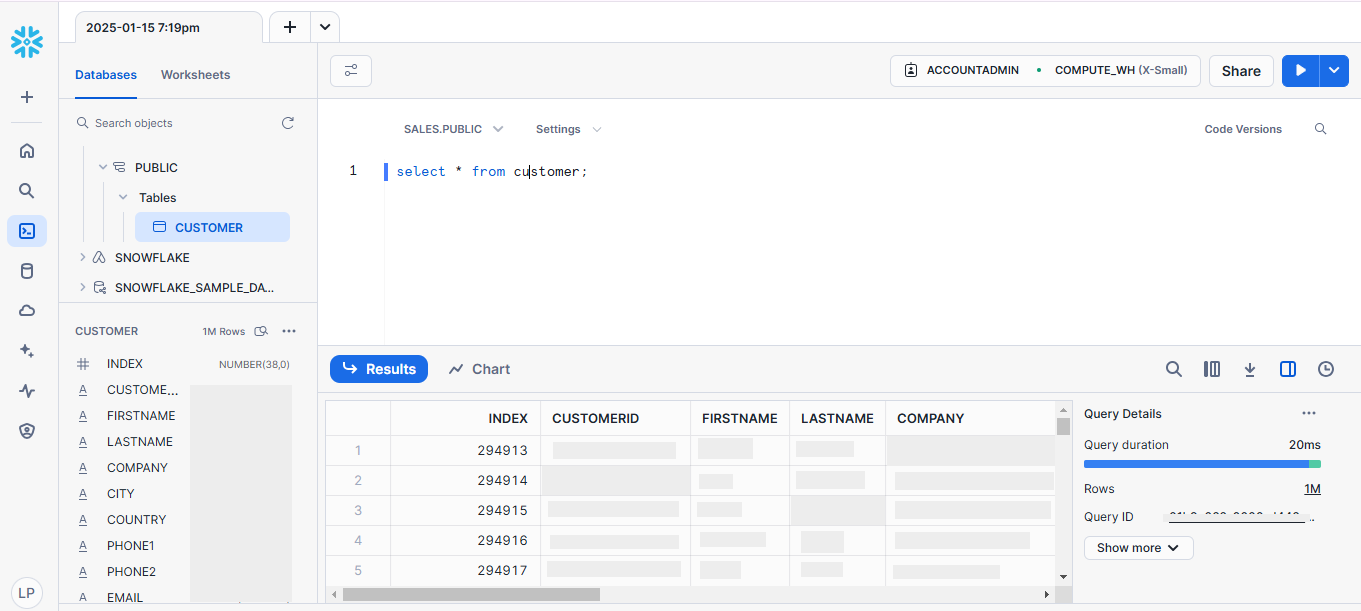
9. Query Performance for rendering 1 million rows is 20 ms. Snowflake took 5+ seconds compared to Apache Druid for querying 1 Million records.
Conclusion
While Snowflake is a powerful, cloud-native data warehouse with strengths in batch processing, historical data analysis, and complex OLAP queries, Apache Druid stands out in scenarios where real-time, low-latency analytics are needed. Druid’s open-source nature, time-series optimizations, streaming data support, and operational focus make it the better choice for real-time analytics, event-driven applications, and fast, interactive querying on large datasets.
Apache Druid FAQ
Apache Druid is used for real-time analytics and fast querying of large-scale datasets. It's particularly suitable for time-series data, clickstream analytics, operational intelligence, and real-time monitoring.
Druid supports:
- Streaming ingestion: Data from Kafka, Kinesis, etc., is ingested in real time.
- Batch ingestion: Data from Hadoop, S3, or other static sources is ingested in batches.
Druid uses:
- Columnar storage: Optimizes storage for analytic queries.
- Advanced indexing: Bitmap and inverted indexes speed up filtering and aggregation.
- Distributed architecture: Spreads query load across multiple nodes.
No. Druid is optimized for OLAP (Online Analytical Processing) and is not suitable for transactional use cases.
- Data is segmented into immutable chunks and stored in Deep Storage (e.g., S3, HDFS).
- Historical nodes cache frequently accessed segments for faster querying.
- SQL: Provides a familiar interface for querying.
- Native JSON-based query language: Offers more flexibility and advanced features.
- Broker: Routes queries to appropriate nodes.
- Historical nodes: Serve immutable data.
- MiddleManager: Handles ingestion tasks.
- Overlord: Coordinates ingestion processes.
- Coordinator: Manages data availability and balancing.
Druid integrates with tools like:
- Apache Superset
- Tableau
- Grafana
- Stream ingestion tools (Kafka, Kinesis)
- Batch processing frameworks (Hadoop, Spark)
Yes, it’s open-source and distributed under the Apache License 2.0.
Alternatives include:
- ClickHouse
- Elasticsearch
- BigQuery
- Snowflake
Whether you're exploring real-time analytics or need help getting started, feel free to reach out!
Watch the Apache Blog Series
Stay tuned for the upcoming Apache Blog Series:
- Exploring Apache Druid: A High-Performance Real-Time Analytics Database
- Unlocking Data Insights with Apache Superset
- Streamlining Apache HOP Workflow Management with Apache Airflow
- Comparison of and migrating from Pentaho Data Integration PDI/ Kettle to Apache HOP
- Apache Druid Integration with Apache Superset
- Why choose Apache Druid over Vertica
- Why choose Apache Druid over Snowflake
- Why choose Apache Druid over Google Big Query
- Integrating Apache Druid with Apache Superset for Realtime Analytics





