
Introduction
In our previous blog, we talked about the Apache HOP in more detail. In case you have missed it, refer to it here “https://analytics.axxonet.com/comparison-of-and-migrating-from-pdi-kettle-to-apache-hop/” page. As a continuation of the Apache HOP article series, here we touch upon how to integrate Apache Airflow and Apache HOP. In the fast-paced world of data engineering and data science, efficiently managing complex workflows is crucial. Apache Airflow, an open-source platform for programmatically authoring, scheduling, and monitoring workflows, has become a cornerstone in many data teams’ toolkits. This blog post explores what Apache Airflow is, its key features, and how you can leverage it to streamline and manage your Apache HOP workflows and pipelines.
Apache HOP
Apache HOP is an open-source data integration and orchestration platform. For more details refer to our previous blog here.
Apache Airflow
Apache Airflow is an open-source workflow orchestration tool originally developed by Airbnb. It allows you to define workflows as code, providing a dynamic, extensible platform to manage your data pipelines. Airflow’s rich features enable you to automate and monitor workflows efficiently, ensuring that data moves seamlessly through various processes and systems.
Use Cases:
- Data Pipelines: Orchestrating ETL jobs to extract data from sources, transform it, and load it into a data warehouse.
- Machine Learning Pipelines: Scheduling ML model training, batch processing, and deployment workflows.
- Task Automation: Running repetitive tasks, like backups or sending reports.
DAG (Directed Acyclic Graph):
- A DAG represents the workflow in Airflow. It defines a collection of tasks and their dependencies, ensuring that tasks are executed in the correct order.
- DAGs are written in Python and allow you to define the tasks and how they depend on each other.
Operators:
- Operators define a single task in a DAG. There are several built-in operators, such as:
- BashOperator: Runs a bash command.
- PythonOperator: Runs Python code.
- SqlOperator: Executes SQL commands.
- HttpOperator: Makes HTTP requests.
Custom operators can also be created to meet specific needs.
Tasks:
- Tasks are the building blocks of a DAG. Each node in a DAG is a task that does a specific unit of work, such as executing a script or calling an API.
- Tasks are defined by operators and their dependencies are controlled by the DAG.
Schedulers:
- The scheduler is responsible for triggering tasks at the appropriate time, based on the schedule_interval defined in the DAG.
- It continuously monitors all DAGs and determines when to run the next task.
Executors:
- The executor is the mechanism that runs the tasks. Airflow supports different types of executors:
- SequentialExecutor: Executes tasks one by one.
- LocalExecutor: Runs tasks in parallel on the local machine.
- CeleryExecutor: Distributes tasks across multiple worker machines.
- KubernetesExecutor: Runs tasks in a Kubernetes cluster.
Web UI:
- Airflow has a web-based UI that lets you monitor the status of DAGs, view logs, and check the status of each task in a DAG.
- It also provides tools to trigger, pause, or retry DAGs.
Key Features of Apache Airflow
Workflow as Code
Airflow uses Directed Acyclic Graphs (DAGs) to represent workflows. These DAGs are written in Python, allowing you to leverage the full power of a programming language to define complex workflows. This approach, known as “workflow as code,” promotes reusability, version control, and collaboration.
Dynamic Task Scheduling
Airflow’s scheduling capabilities are highly flexible. You can schedule tasks to run at specific intervals, handle dependencies, and manage task retries in case of failures. The scheduler executes tasks in a defined order, ensuring that dependencies are respected and workflows run smoothly.
Extensible Architecture
Airflow’s architecture is modular and extensible. It supports a wide range of operators (pre-defined tasks), sensors (waiting for external conditions), and hooks (interfacing with external systems). This extensibility allows you to integrate with virtually any system, including databases, cloud services, and APIs.
Robust Monitoring and Logging
Airflow provides comprehensive monitoring and logging capabilities. The web-based user interface (UI) offers real-time visibility into the status of your workflows, enabling you to monitor task progress, view logs, and troubleshoot issues. Additionally, Airflow can send alerts and notifications based on task outcomes.
Scalability and Reliability
Designed to scale, Airflow can handle workflows of any size. It supports distributed execution, allowing you to run tasks on multiple workers across different nodes. This scalability ensures that Airflow can grow with your organization’s needs, maintaining reliability even as workflows become more complex.
Getting Started with Apache Airflow
Installation using PIP
Setting up Apache Airflow is straightforward. You can install it using pip, Docker, or by deploying it on a cloud service. Here’s a brief overview of the installation process using pip:
1. Create a Virtual Environment (optional but recommended):
python3 -m venv airflow_env
source airflow_env/bin/activate
2. Install Apache Airflow:
pip install apache-airflow
3. Initialize the Database:
airflow db init
4. Create a User:
airflow users create –username admin –password admin –firstname Admin – lastname User –role Admin –email admin@example.com
5. Start the Web Server and Scheduler:
airflow webserver –port 8080
airflow scheduler
6. Access the Airflow UI: Open your web browser and go to http://localhost:8080.
Installation using Docker
Pull the docker image and run the container to access the Airflow web UI. Refer to the link for more details.
Creating Your First DAG
Airflow DAG Structure:
A DAG in Airflow is composed of three main parts:
- Imports: Necessary packages and operators.
- Default Arguments: Arguments that apply to all tasks within the DAG (such as retries, owner, start date).
- Task Definition: Define tasks using operators, and specify dependencies between them.
Scheduling:
Airflow allows you to define the schedule of a DAG using schedule_interval:
- @daily: Run once a day at midnight.
- @hourly: Run once every hour.
- @weekly: Run once a week at midnight on Sunday.
- Cron expressions, like “0 12 * * *”, are also supported for more specific scheduling needs.
- Define the DAG: Create a Python file (e.g., run_lms_transaction.py) in the dags folder of your Airflow installation directory.
Example:
from airflow import DAG from airflow.operators.dummy import DummyOperator from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2023, 1, 1), ‘retries’: 1, } dag = DAG(‘example_dag’, default_args=default_args, schedule_interval=‘@daily’) start = DummyOperator(task_id=‘start’, dag=dag) end = DummyOperator(task_id=‘end’, dag=dag) start >> end |
2. Deploy the DAG: Save the file in the Dags folder. Place the DAG Python script in the DAGs folder (~/airflow/dags by default). Airflow will automatically detect and load the DAG.
3. Monitor the DAG: Access the Airflow UI, where you can view and manage the newly created DAG. Trigger the DAG manually or wait for it to run according to the defined schedule.
Calling the Apache HOP Pipelines/Workflows from Apache Airflow
In this example, we walk through how to integrate the Apache HOP with Apache Airflow. Here both the Apache Airflow and Apache HOP are running on two different independent docker containers. Apache HOP ETL Pipelines / Workflows are configured with a persistent volume storage strategy so that the DAG code can request execution from Airflow.
Steps
- Define the DAG: Create a Python file (e.g., Stg_User_Details.py) in the dags folder of your Airflow installation directory.
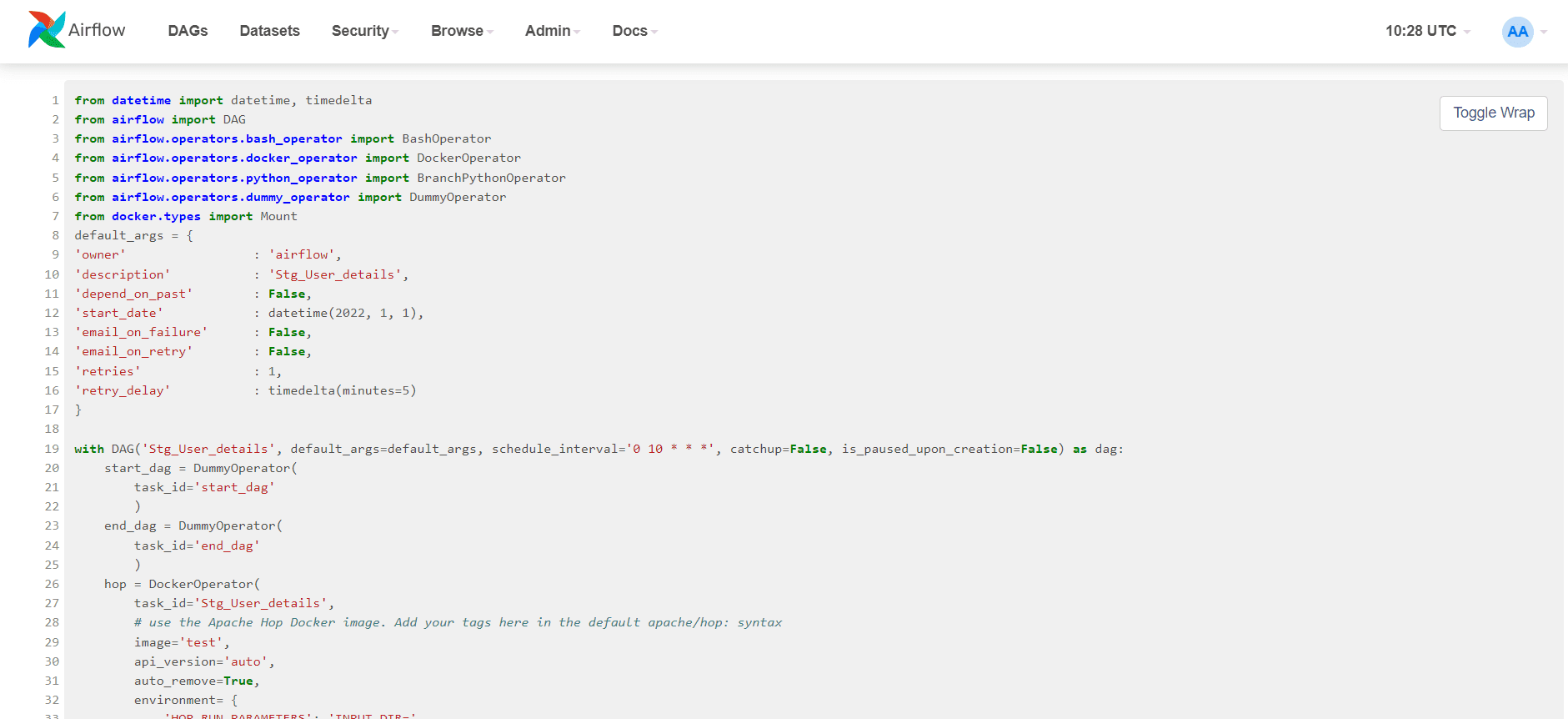
from datetime import datetime, timedelta from airflow import DAG from airflow.operators.bash_operator import BashOperator from airflow.operators.docker_operator import DockerOperator from airflow.operators.python_operator import BranchPythonOperator from airflow.operators.dummy_operator import DummyOperator from docker.types import Mount default_args = { ‘owner’ : ‘airflow’, ‘description’ : ‘Stg_User_details’, ‘depend_on_past’ : False, ‘start_date’ : datetime(2022, 1, 1), ’email_on_failure’ : False, ’email_on_retry’ : False, ‘retries’ : 1, ‘retry_delay’ : timedelta(minutes=5) } with DAG(‘Stg_User_details’, default_args=default_args, schedule_interval=‘0 10 * * *’, catchup=False, is_paused_upon_creation=False) as dag: start_dag = DummyOperator( task_id=‘start_dag’ ) end_dag = DummyOperator( task_id=‘end_dag’ ) hop = DockerOperator( task_id=‘Stg_User_details’, # use the Apache Hop Docker image. Add your tags here in the default apache/hop: syntax image=‘test’, api_version=‘auto’, auto_remove=True, environment= { ‘HOP_RUN_PARAMETERS’: ‘INPUT_DIR=’, ‘HOP_LOG_LEVEL’: ‘TRACE’, ‘HOP_FILE_PATH’: ‘/opt/hop/config/projects/default/stg_user_details_test.hpl’, ‘HOP_PROJECT_DIRECTORY’: ‘/opt/hop/config/projects/’, ‘HOP_PROJECT_NAME’: ‘ISON_Project’, ‘HOP_ENVIRONMENT_NAME’: ‘ISON_Env’, ‘HOP_ENVIRONMENT_CONFIG_FILE_NAME_PATHS’: ‘/opt/hop/config/projects/default/project-config.json’, ‘HOP_RUN_CONFIG’: ‘local’, }, docker_url=“unix://var/run/docker.sock”, network_mode=“bridge”, force_pull=False, mount_tmp_dir=False ) start_dag >> hop >> end_dag |
Note: For reference purposes only.
2. Deploy the DAG: Save the file in the dags folder. Airflow will automatically detect and load the DAG.
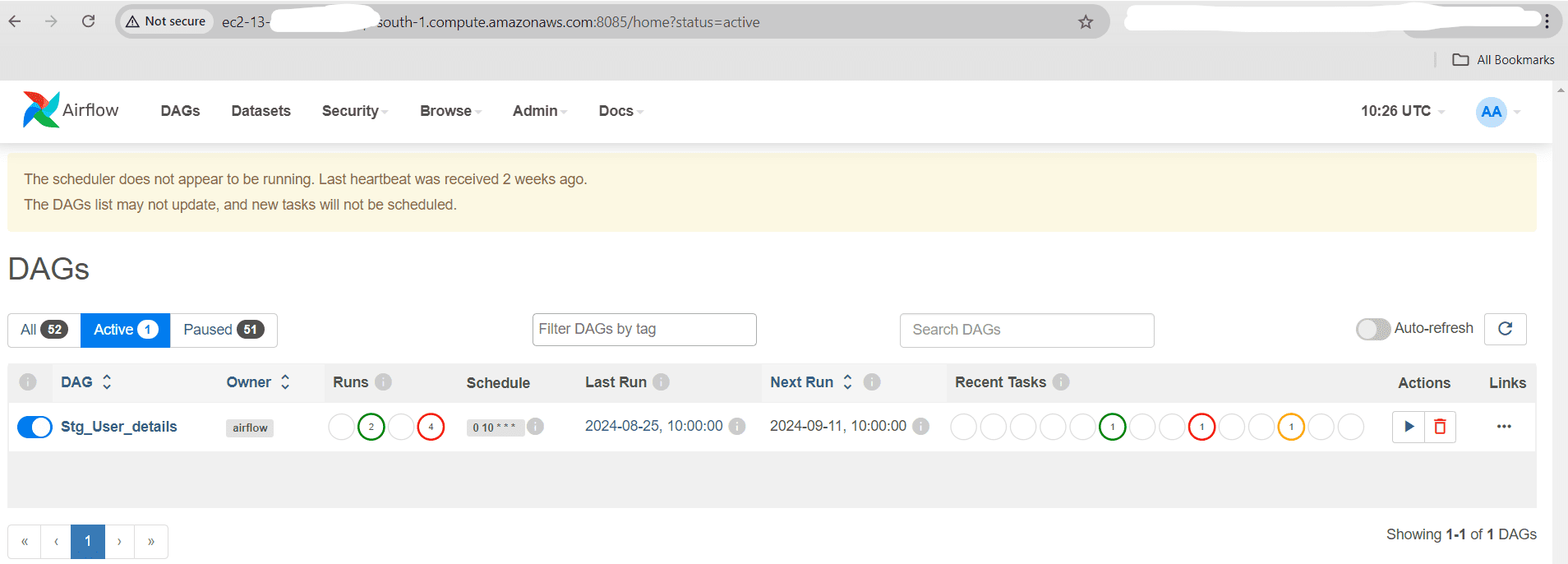
After successful deployment, we should see the new “Stg_User_Details” DAG listed in the Active Tab and All Tab from the Airflow Portal. As shown in the screenshot above.
3. Run the DAG: We can trigger pipelines or workflows using Airflow by clicking on the Trigger DAG option as shown below from the Airflow application.

4. Monitor the DAG: Access the Airflow UI, where you can view and manage the newly created DAG. Trigger the DAG manually or wait for it to run according to the defined schedule.
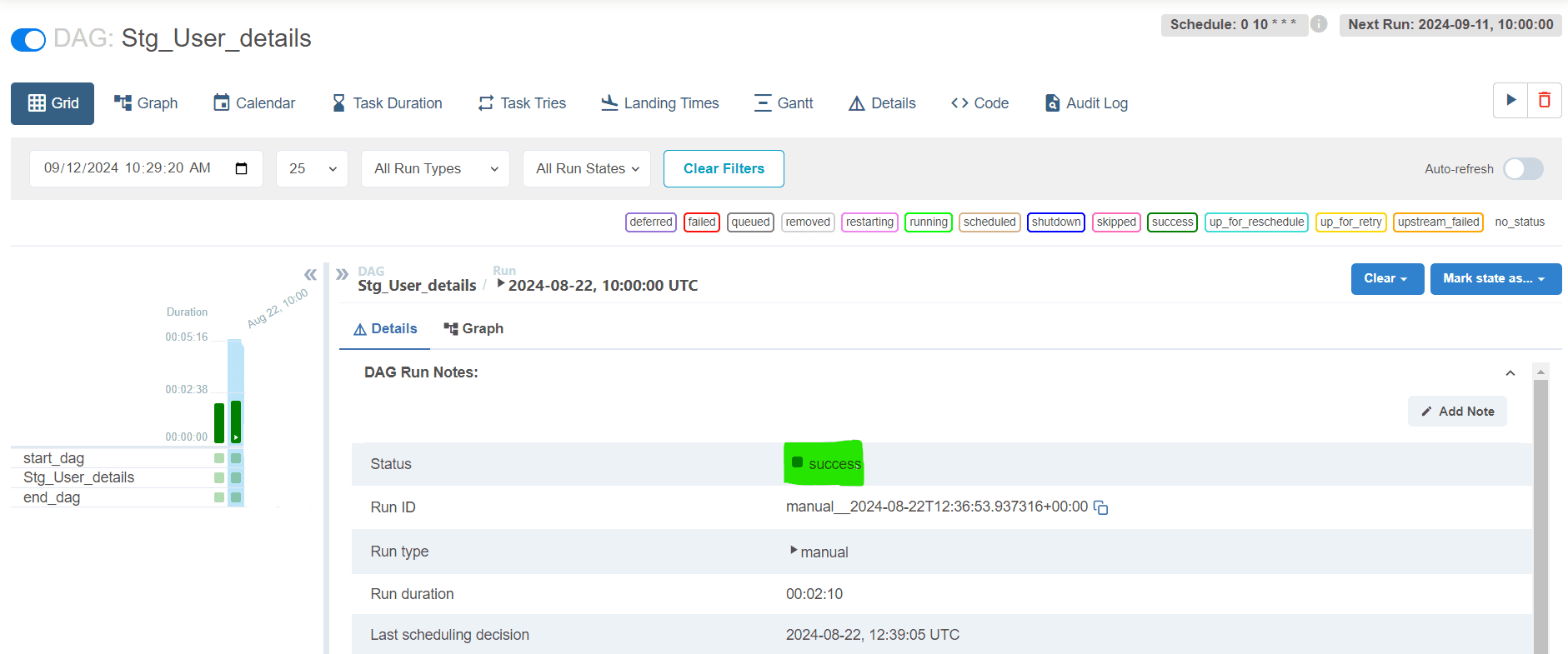
After successful execution, we should see the status message as shown an execution history along with log details. new “Stg_User_Details” DAG listed in the Active Tab and All Tab from the Airflow Portal. As shown in the screenshot above.
Managing and Scaling Workflows
- Use Operators and Sensors: Leverage Airflow’s extensive library of operators and sensors to create tasks that interact with various systems and handle complex logic.
- Implement Task Dependencies: Define task dependencies using the >> and << operators to ensure tasks run in the correct order.
- Optimize Performance: Monitor task performance through the Airflow UI and logs. Adjust task configurations and parallelism settings to optimize workflow execution.
- Scale Out: Configure Airflow to run in a distributed mode by adding more worker nodes, ensuring that the system can handle increasing workload efficiently.
Conclusion
Apache Airflow is a powerful and versatile tool for managing workflows and automating complex data pipelines. Its “workflow as code” approach, coupled with robust scheduling, monitoring, and scalability features, makes it an essential tool for data engineers and data scientists. By adopting Airflow, you can streamline your workflow management, improve collaboration, and ensure that your data processes are efficient and reliable. Explore Apache Airflow today and discover how it can transform your data engineering workflows.
Streamline your Apache HOP Workflow Management With Apache Airflow through our team of experts.
Upcoming Apache HOP Blog Series
Stay tuned for the upcoming Apache HOP Blog Series:
- Migrating from Pentaho ETL to Apache Hop
- Integrating Apache Hop with an Apache Superset
- Comparison of Pentaho ETL and Apache Hop





