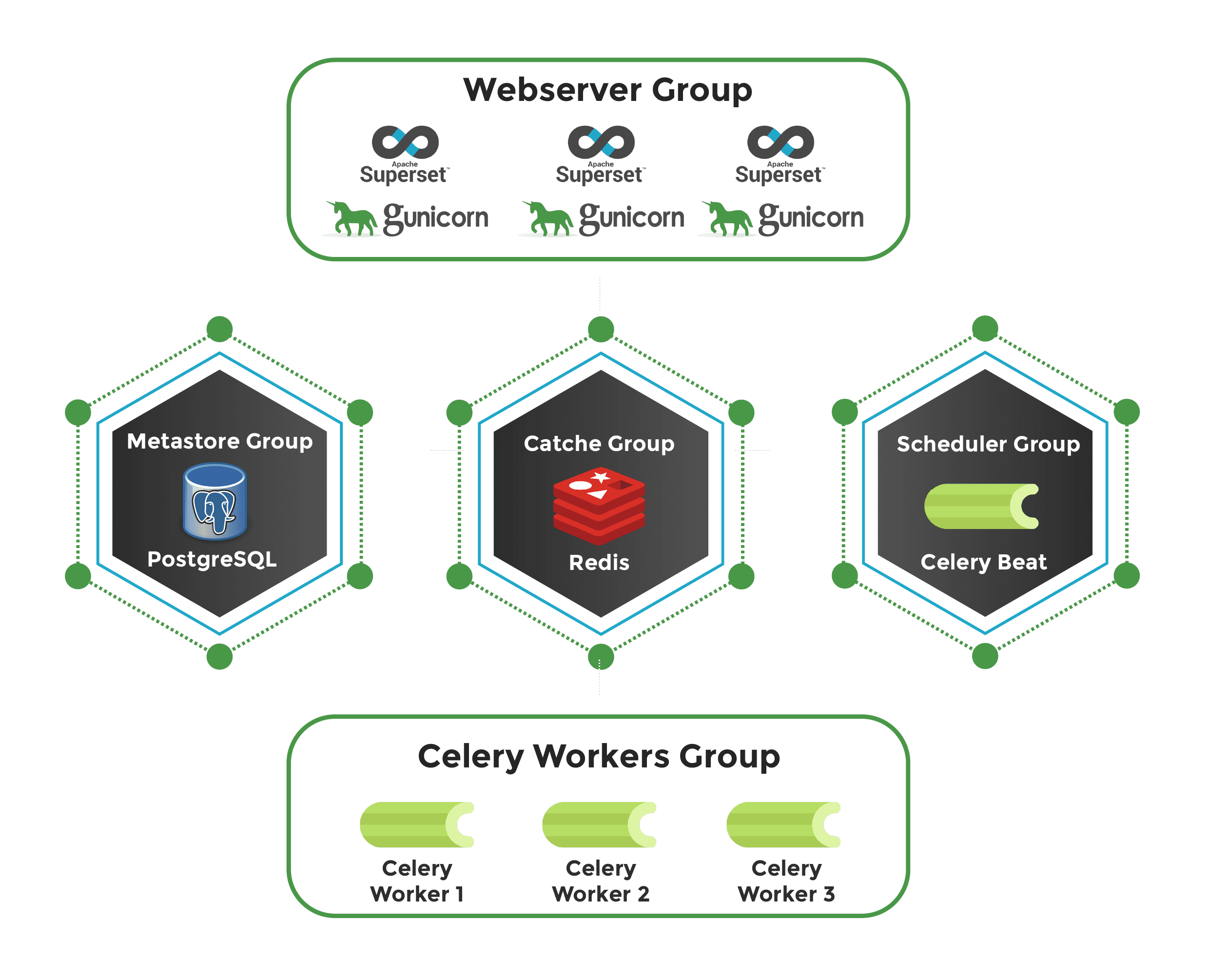
Introduction
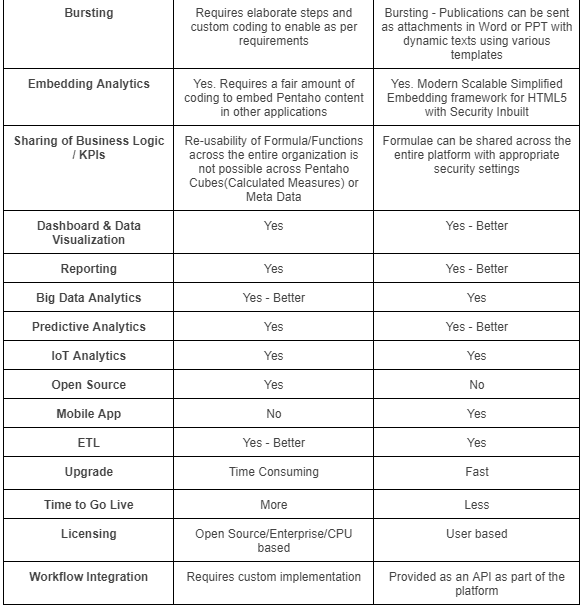
In our previous blog, we discussed Apache HOP in more detail. In case you have missed it, refer to Comparison of and migrating from Pentaho Data Integration PDI/ Kettle to Apache HOP. As a continuation of the Apache HOP article series, here we touch upon how to integrate Apache HOP with GitLab for version management and CI/CD.
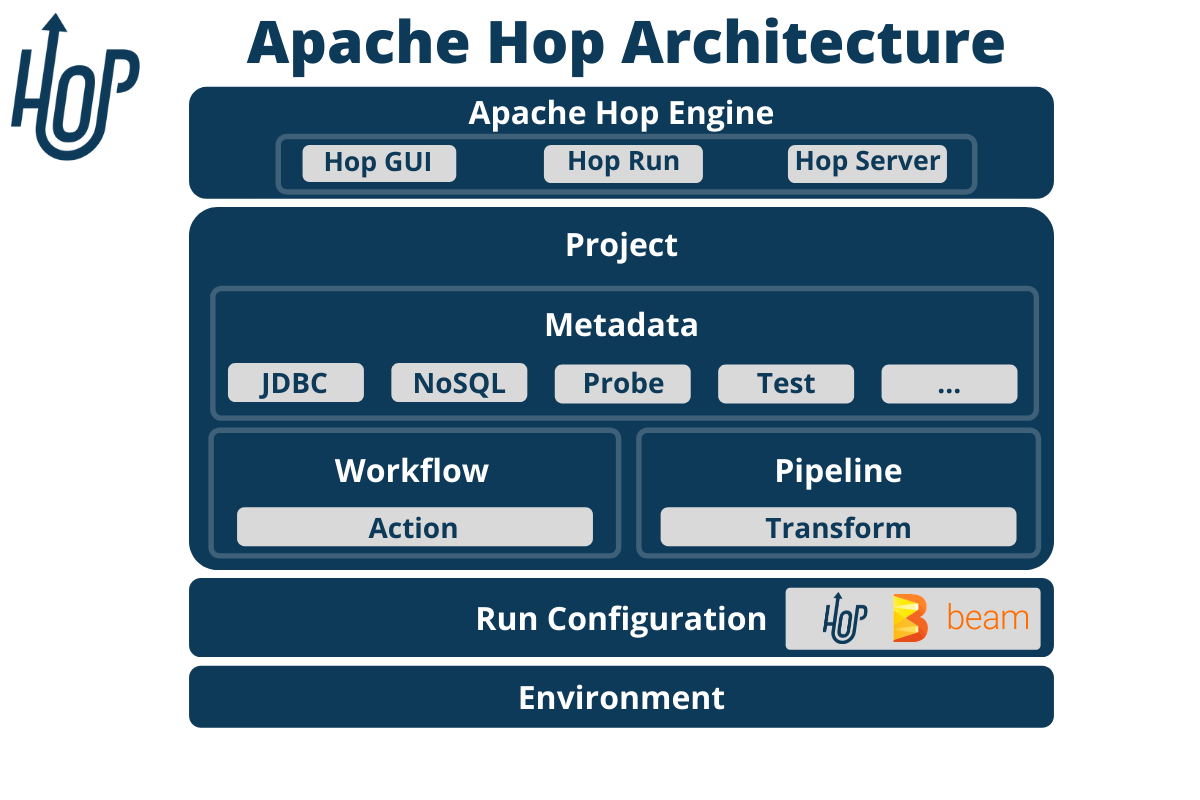
In the fast-paced world of data engineering and data science, organizations deal with massive amounts of data that need to be processed, transformed, and analyzed in real-time. Extract, Transform, and Load (ETL) workflows are at the heart of this process, ensuring that raw data is ingested, cleaned, and structured for meaningful insights. Apache HOP (Hop Orchestration Platform) has emerged as one of the most powerful open-source tools for designing, orchestrating, and executing ETL pipelines, offering a modular, scalable, and metadata-driven approach to data integration.
However, as ETL workflows become more complex and business requirements evolve quickly, managing multiple workflows can be difficult. This is where Continuous Integration and Continuous Deployment (CI/CD) come into play. By automating the deployment, testing, and version control of ETL pipelines, CI/CD ensures consistency, reduces human intervention, and accelerates the development lifecycle.
This blog post explores Apache HOP integration with Gitlab, its key features, and how to leverage it to streamline and manage your Apache HOP workflows and pipelines.
Apache Hop:
Apache Hop (Hop Orchestration Platform) is a robust, open-source data integration and orchestration tool that empowers developers and data engineers to build, test, and deploy workflows and pipelines efficiently. One of Apache Hop’s standout features is its seamless integration with version control systems like Git, enabling collaborative development and streamlined management of project assets directly from the GUI.
GitLab:
GitLab is a widely adopted DevSecOps platform that provides built-in CI/CD capabilities, version control, and infrastructure automation. Integrating GitLab with Apache HOP for ETL development and deployment offers several benefits:
- Version Control for ETL Workflows
- GitLab allows teams to track changes in Apache HOP pipelines, making it easier to collaborate, review, and revert to previous versions when needed.
- Each change to an ETL workflow is documented, ensuring transparency and traceability in development.
- Automated Testing of ETL Pipelines
- Data pipelines can break due to schema changes, logic errors, or unexpected data patterns.
- GitLab CI/CD enables automated testing of HOP pipelines before deployment, reducing the risk of failures in production.
- Seamless Deployment to Multiple Environments
- Using GitLab CI/CD pipelines, teams can deploy ETL workflows across different environments (development, staging, and production) without manual intervention.
- Environment-specific configurations can be managed efficiently using GitLab variables.
- Efficient Collaboration & Code Reviews
- Multiple data engineers can work on different aspects of ETL development simultaneously using GitLab’s branching and merge request features.
- Code reviews ensure best practices are followed, improving the quality of ETL pipelines.
- Rollback and Disaster Recovery
- If an ETL workflow fails in production, previous stable versions can be quickly restored using GitLab’s versioning and rollback capabilities.
- Security and Compliance
- GitLab provides access control, audit logging, and security scanning features to ensure that sensitive ETL workflows adhere to compliance standards.
Jenkins:
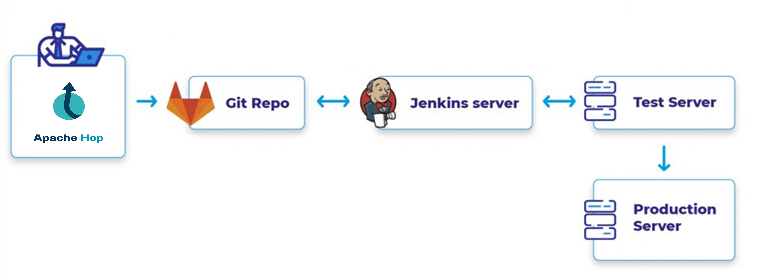
Jenkins, one of the most widely used automation servers, plays a key role in enabling CI/CD by automating build, test, and deployment processes. Stay tuned for our upcoming articles on How to Integrate Jenkins with GitLab for managing, and deploying the Apache HOP artifacts.
In this blog post, we’ll explore how Git actions can be utilized in Apache Hop GUI to manage and track changes to workflows and pipelines effectively. We’ll cover the setup process, common Git operations, and best practices for using Git within Apache Hop.
Manual Git Integration for CI/CD Process (Problem Statement)
Earlier CI/CD for ETLs was a manual and tedious process. In ETL tools like Pentaho PDI or the older versions, we had to manually manage the CICD for the ETL artefacts (Apache Hop or Pentaho pipelines/transformation and workflows/jobs) with Git by following these summary steps:
- Create an Empty Repository
- Log in to your Git account.
- Create a new repository and leave it empty (do not add a README, .gitignore, or license file).
- Clone the Repository
- Clone the empty repository to your local system.
- This will create a local folder corresponding to your repository.
- Use the Cloned Folder as Project Home
- Set the cloned folder as your Apache Hop project home folder.
- Save all your pipelines (.hpl files), workflows (.hwf files), and configuration files in this folder.
Common Challenges in Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI), also known as Kettle, has been widely used for ETL (Extract, Transform, Load) processes. However, as data workflows became more complex and teams required better collaboration, automation, and version control, Pentaho’s limitations in CI/CD (Continuous Integration/Continuous Deployment) and Git integration became apparent.
1. Lack of Native Git Support
- PDI lacked built-in Git integration, making version control and collaboration difficult for teams working on large-scale data projects.
2. Manual Deployment Processes
- Without automated CI/CD pipelines, teams had to manually deploy and migrate transformations, leading to inefficiencies and errors.
3. Limited Workflow Orchestration
- Handling complex workflows required custom scripting and external tools, increasing development overhead.
4. Scalability Issues:
- PDI struggled with modern cloud-native architectures and containerized deployments, requiring additional customization.
Official Link: https://pentaho-public.atlassian.net/jira/software/c/projects/PDI
Birth of Apache Hop (Solution)
- Built-in Git Integration: Enables seamless version control, collaboration, and tracking of changes within the Hop GUI.
- CI/CD Compatibility: Supports automated testing, validation, and deployment of workflows using tools like Jenkins, GitHub Actions, and GitLab CI/CD.
- Improved Workflow Orchestration: Provides metadata-driven workflow design with enhanced debugging and visualization.
- Containerization & Cloud Support: Fully supports Kubernetes, Docker, and cloud-native architectures for scalable deployments.
Impact of Git and CI/CD in Apache Hop
The integration of Git and Continuous Integration/Continuous Deployment (CI/CD) practices into Apache Hop has significantly transformed the way data engineering teams manage and deploy their ETL workflows.
1. Enhanced Collaboration with Git
Apache Hop’s support for Git allows multiple team members to work on different parts of a data pipeline simultaneously. Each developer can clone the repository, make changes in isolated branches, and submit pull requests for review. Git’s version control enables teams to:
- Track changes to workflows and metadata over time
- Review historical modifications and troubleshoot regressions
- Merge contributions efficiently while minimizing conflicts
This collaborative environment leads to better code quality, transparency, and accountability within the team.
2. Reliable Deployments through CI/CD Pipelines
By integrating Apache Hop with CI/CD tools like Jenkins, GitLab CI, or GitHub Actions, organizations can automate the process of testing, packaging, and deploying ETL pipelines. Benefits include:
- Automated testing of workflows to ensure stability before production releases
- Consistent deployment across development, staging, and production environments
- Rapid iteration cycles, reducing the time from development to delivery
These pipelines reduce human error and enhance the repeatability of deployment processes.
3. Improved Agility and Scalability
The combination of Git and CI/CD fosters a modern DevOps culture within data engineering. Teams can:
- React quickly to changing business requirements
- Scale solutions across projects and environments with minimal overhead
- Maintain a centralized repository for configuration and infrastructure-as-code artifacts
This level of agility makes Apache Hop a powerful and future-ready tool for enterprises aiming to modernize their data integration and transformation processes.
Why Use Git with Apache Hop?
Integrating Git with Apache Hop offers several benefits:
- Version Control
- Track changes in pipelines and workflows with Git’s version history.
- Revert to previous versions when needed.
- Collaboration
- Multiple users can work on the same repository, ensuring smooth collaboration.
- Resolve conflicts using Git’s merge and conflict resolution features.
- Centralized Management
- Store pipelines, workflows, and associated metadata in a Git repository for centralized access.
- Branch Management
- Experiment with new features or workflows in isolated branches.
- Rollback
- Revert to earlier versions of workflows in case of issues.
By incorporating Git into your Apache Hop workflow, you ensure a smooth and organized development process.
Git Actions in Apache Hop GUI
Apache Hop GUI provides a range of Git-related actions to simplify version control tasks.
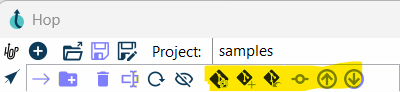
These actions can be accessed from the toolbar or context menus within the application.
- Committing Changes
- After modifying a workflow or pipeline, save the changes.
- Use the Commit option in the GUI to add a descriptive message for the changes.
- Pulling Updates
- Fetch the latest changes from the remote repository using the Pull option.
- Resolve any conflicts directly in the GUI or using an external merge tool.
- Pushing Changes
- Once you commit changes locally, use the Push option to sync them with the remote repository.
- Branching and Merging
- Create new branches for feature development or experimentation.
- Merge branches into the main branch to integrate completed features.
- Viewing History
- View the commit history to understand changes made to workflows or pipelines over time.
- Use the diff viewer to compare changes between commits.
- Reverting Changes
- If a workflow is not functioning as expected, revert to a previous commit directly from the GUI.
In addition to adding and committing files, Apache Hop’s File Explorer perspective allows you to manage other Git operations:
- Pull: To retrieve the latest changes from your remote repository, click the Git Pull button in the toolbar. This ensures you’re always working with the most up-to-date version of the project.
- Revert: If you need to discard changes to a file or folder, select the file and click Git Revert in the Git toolbar.
- Visual Diff: Apache Hop allows you to visually compare different versions of a file. Click the Git Info button, select a specific revision, and use the Visual Diff option to see the changes between two versions of a pipeline or workflow. This opens two tabs, showing the before and after states of your project.
Setting Up Git in Apache Hop GUI (CI/CD)
Apache Hop (Hop Orchestration Platform) provides Git integration to help users manage their workflows, pipelines, and metadata effectively. This integration allows version control of Hop projects, making it easier to track changes, collaborate, and revert to previous versions.
Apache Hop supports Git integration to track metadata changes such as:
- Pipelines (ETL workflows)
- Workflows (job orchestration)
- Project metadata (variables, environment settings)
- Database connections (stored securely)
With Git, users can:
- Commit and push changes to a repository
- Revert changes
- Collaborate with other team members
- Maintain a version history of Hop projects
Prerequisites
- Install Apache Hop on your system.
- Set up Git on your machine and configure it with your credentials (username and email).
- Ensure you have access to a Git repository (local or remote).
- Create or clone a repository to store Apache Hop files.
Create a GitLab access token to authenticate and push the code artifacts from Apache HOP.
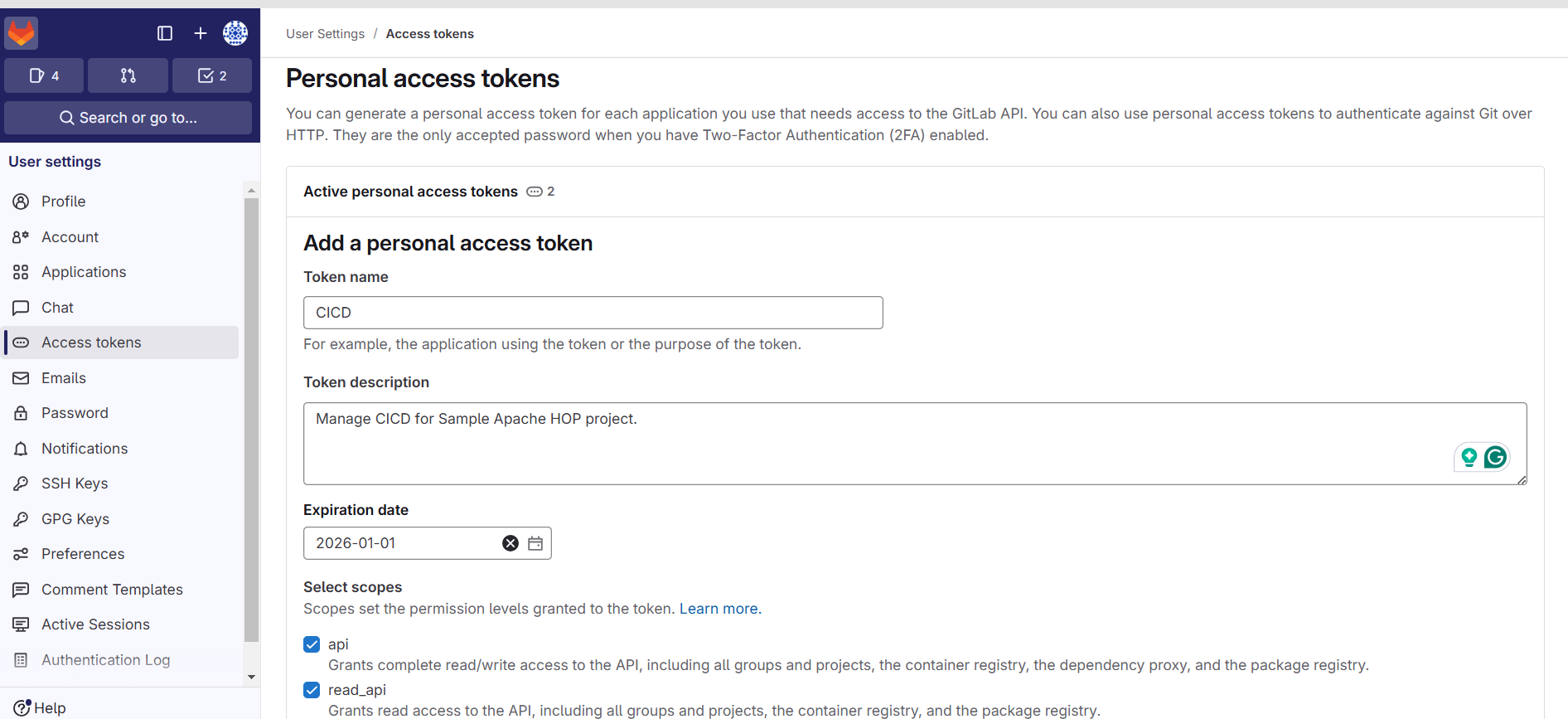
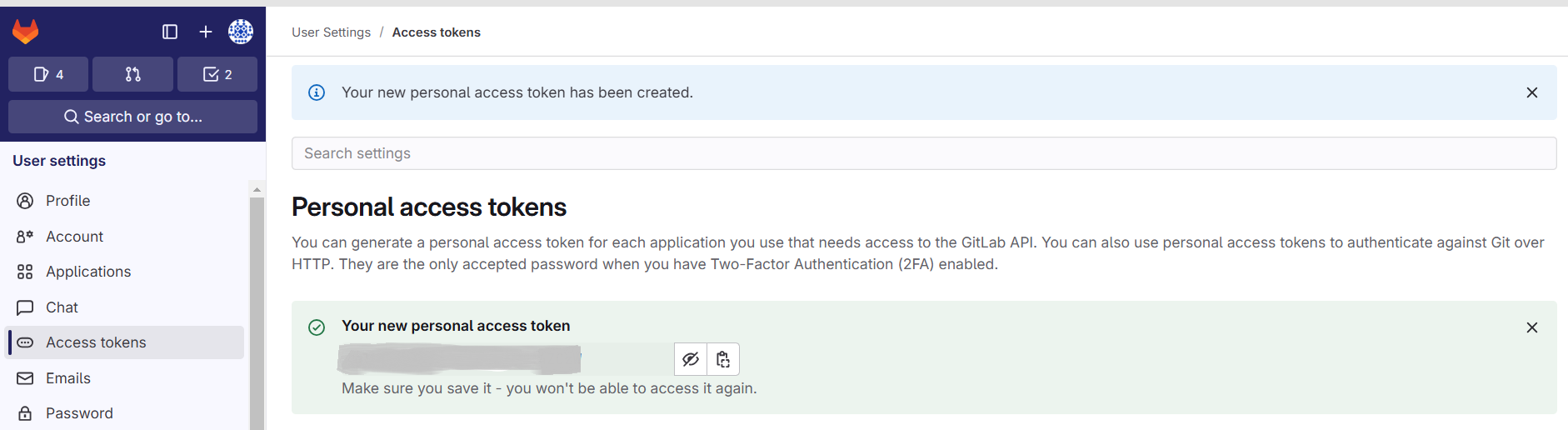
Configure Git in Apache Hop
Here are the steps for configuring the CICD process using Gitlab in Apache HOP
Step 1: Launch Apache Hop GUI
Step 2: Navigate to the Preferences Menu
Step 3: Locate the Version Control Settings and Configure the Path to your Git Executable
Step 4: Optionally, Specify Default Repositories and Branch Names for your Projects
Step 5: Initialize a Git Repository
- Create a new project in Apache Hop.
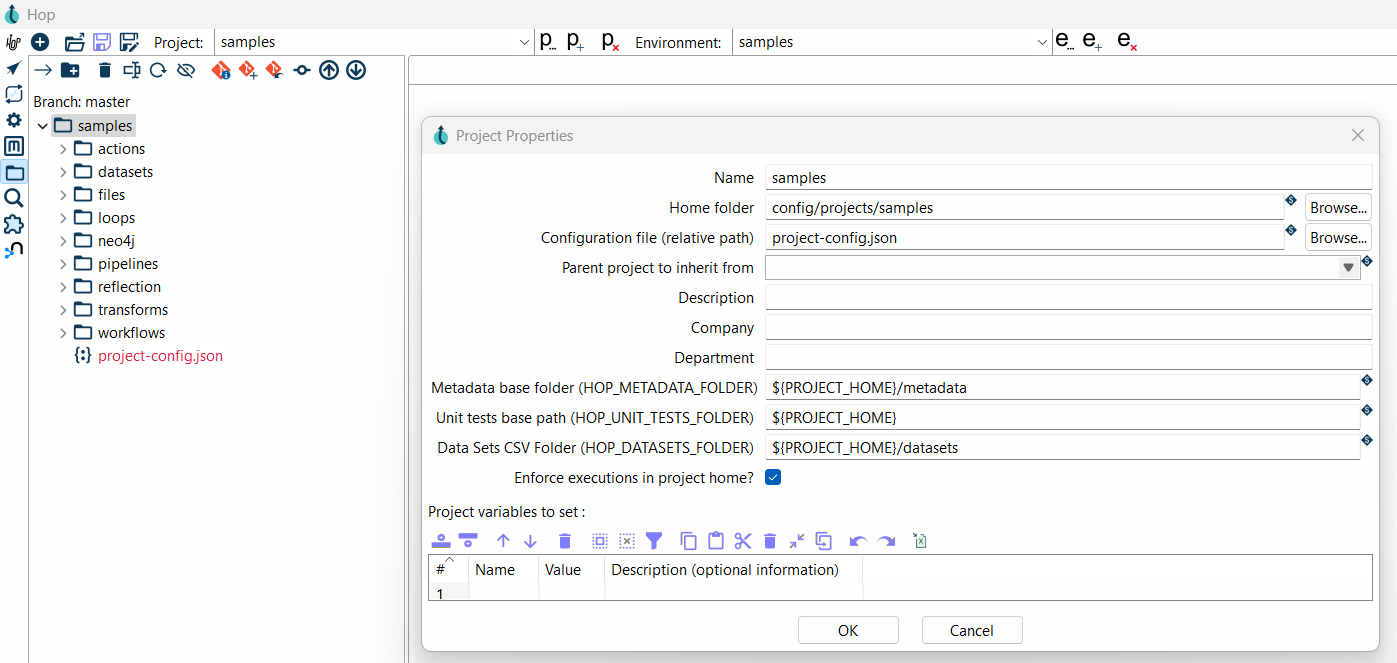
- Open and verify the project’s folder in your file system.
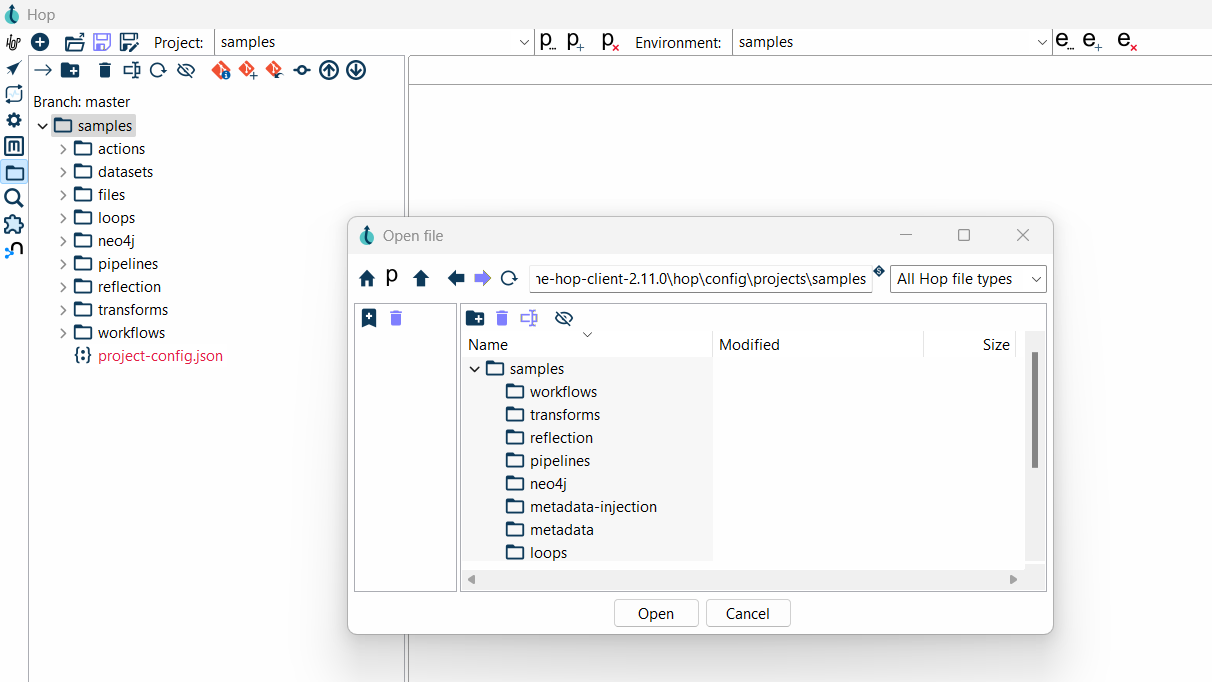
- Use Git to initialize the repository: Run the Init command in the Hop Project folder.
$ git init

- Add a .gitignore file to exclude temporary files generated by Hop:
- *.log
- *.bak
Step 6: Git Info
- After successfully initializing the Git on your local Hop project folder.
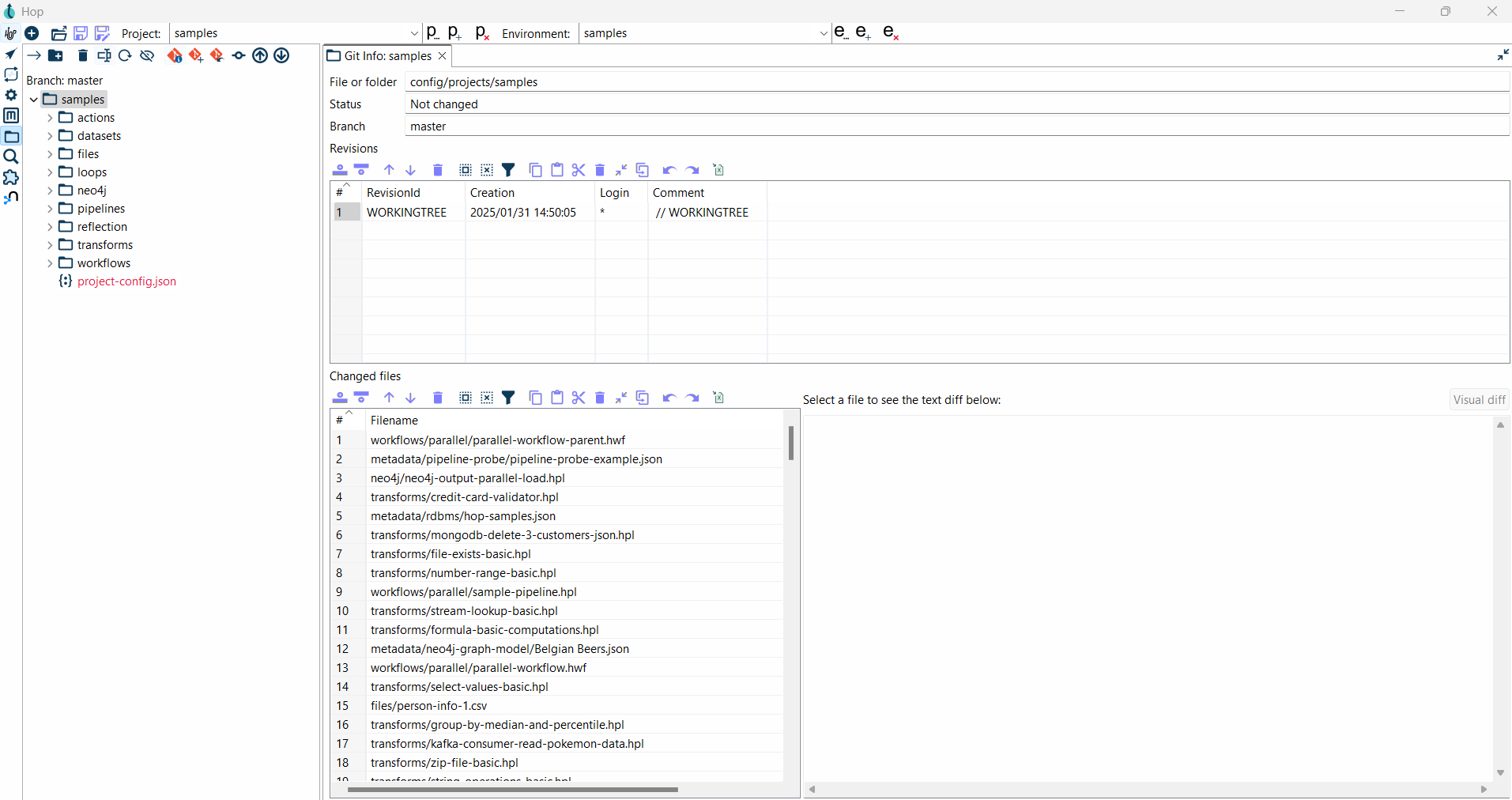
Step 7: Adding Files to Git
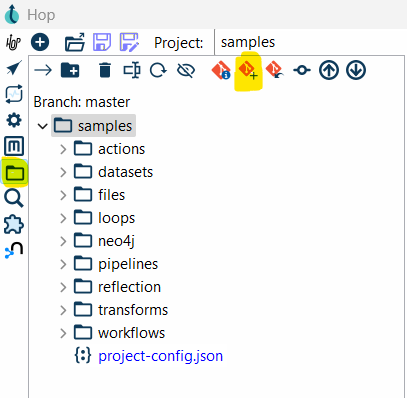
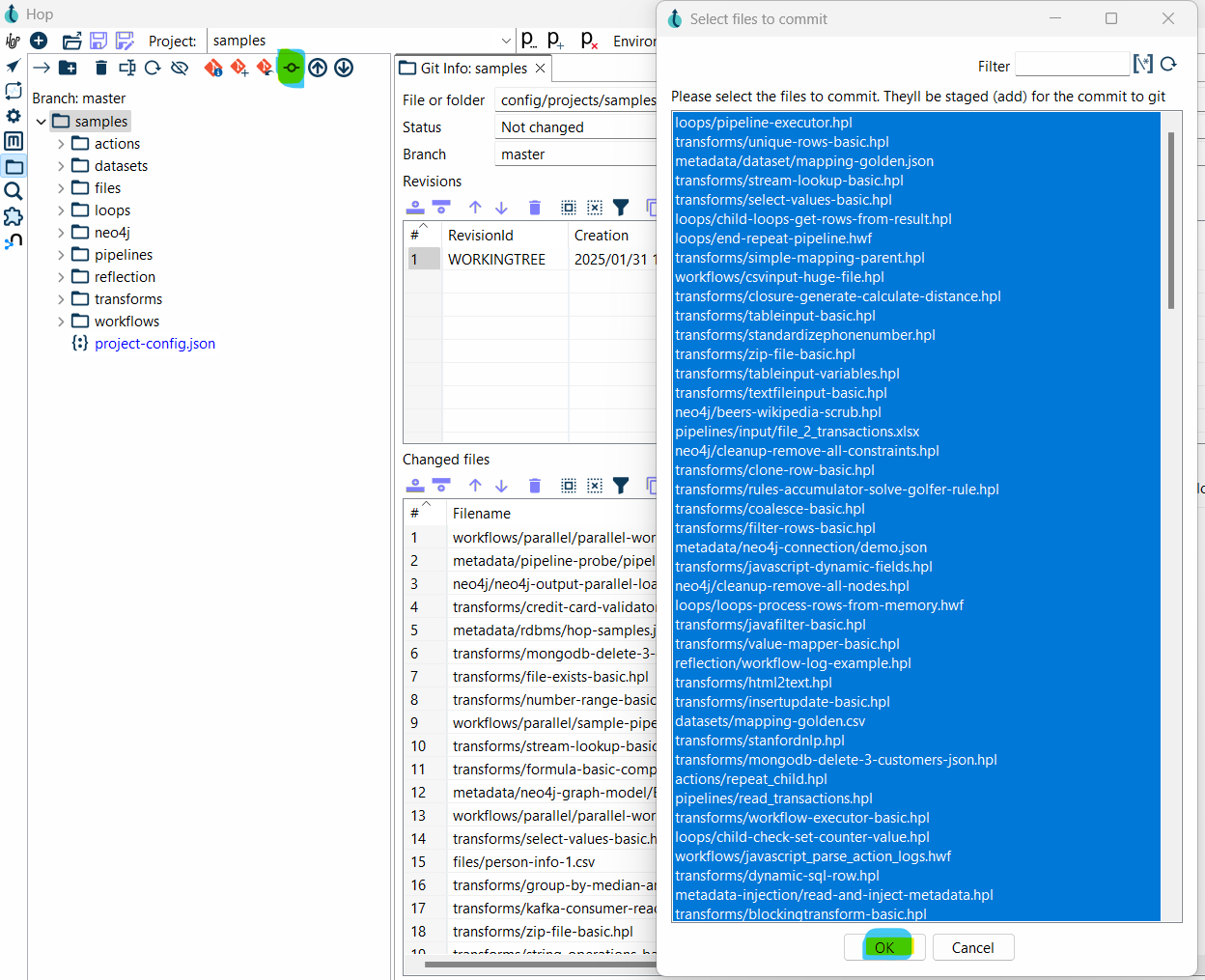
- Select the file(s) you want to add to Git from the File Explorer.
- In the toolbar at the top, you’ll see the Git Add button. Clicking this will stage the selected files, meaning they’re ready to be committed to your Git repository.
- Alternatively, right-click the file in the File Explorer and select Git Add.
Once staged, the file will change from red to blue, indicating that it’s ready to be committed.
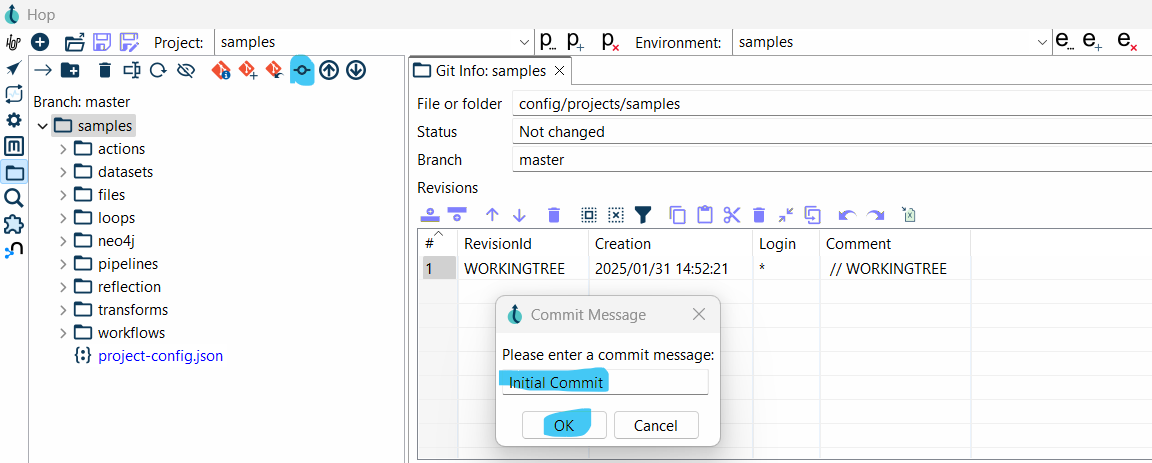
Step 8: Committing Changes
- Click the Git Commit button from the toolbar.
- Select the files you’ve staged from the File Explorer that you want to include in the commit.
- A dialog will prompt you to enter a commit message, this message should summarize the changes you’ve made. Confirm the commit.
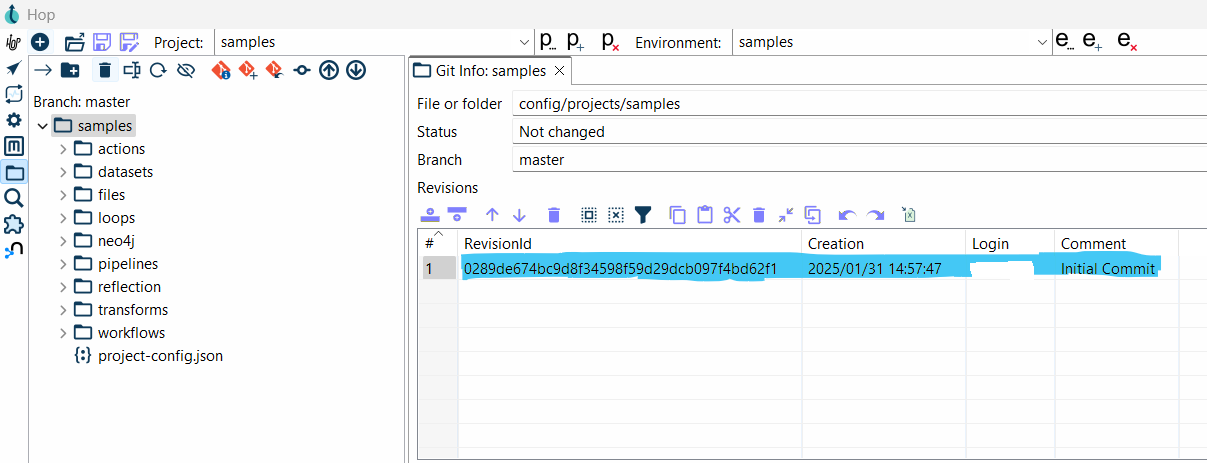
Once committed, the blue files will return to a neutral color.
- After a successful Commit, comment details are shown in the Revision Tab.
Step 9: Connect to a Remote Repository
Add a remote repository URL:
git remote add origin <repository_url>

- Push the local repository to the remote repository:
git push -u origin main
Step 10: Pushing Changes to a Remote Repository
- In the Git toolbar, click the Git Push button.
- Apache Hop will prompt you for your Git username and password. Enter the correct authentication details.
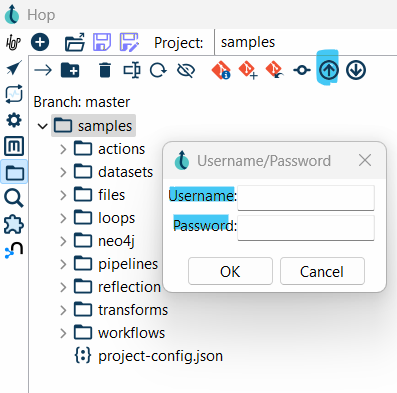
- A confirmation message will appear, indicating that the push was successful.
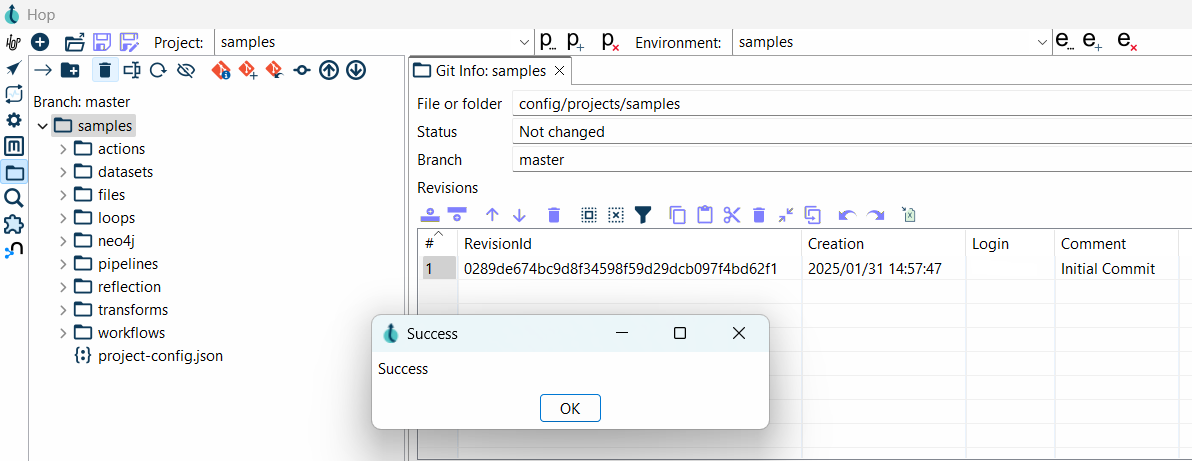
GitLab / GitHub Operation
In the previous section of this blog, we have seen how to practically initialize a new Git project, commit the ETL files, and push the ETLs and config files from the Apache HOP GUI tool. This section will show how to manage merges and approve merge requests in GitLab after sending the push request from Apache HOP.
- Go to the GitLab project.
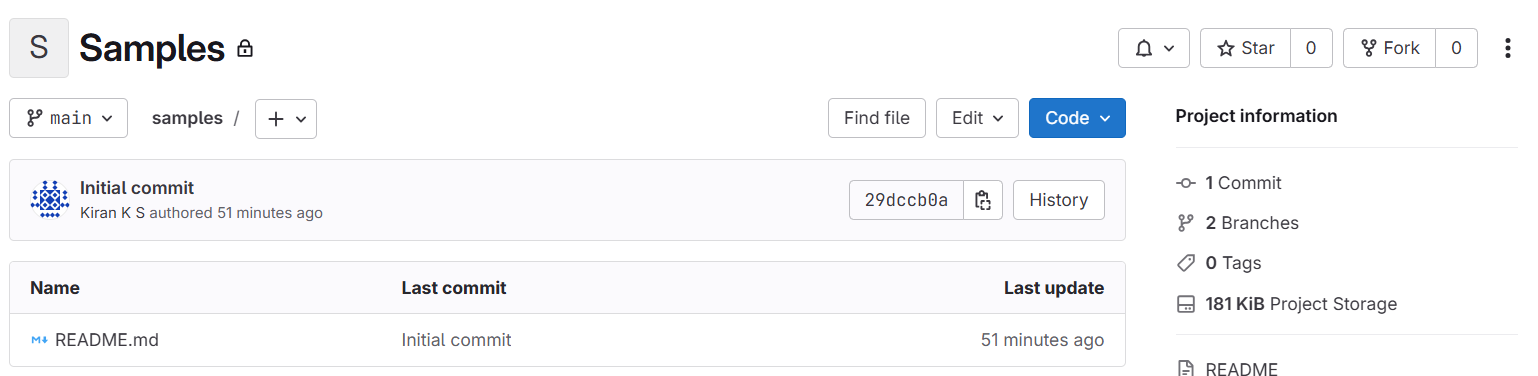
Once the code is pushed from Hop, you should able to see the merge request notification as shown below:

2. Create a Merge request in the GitLab as shown below:
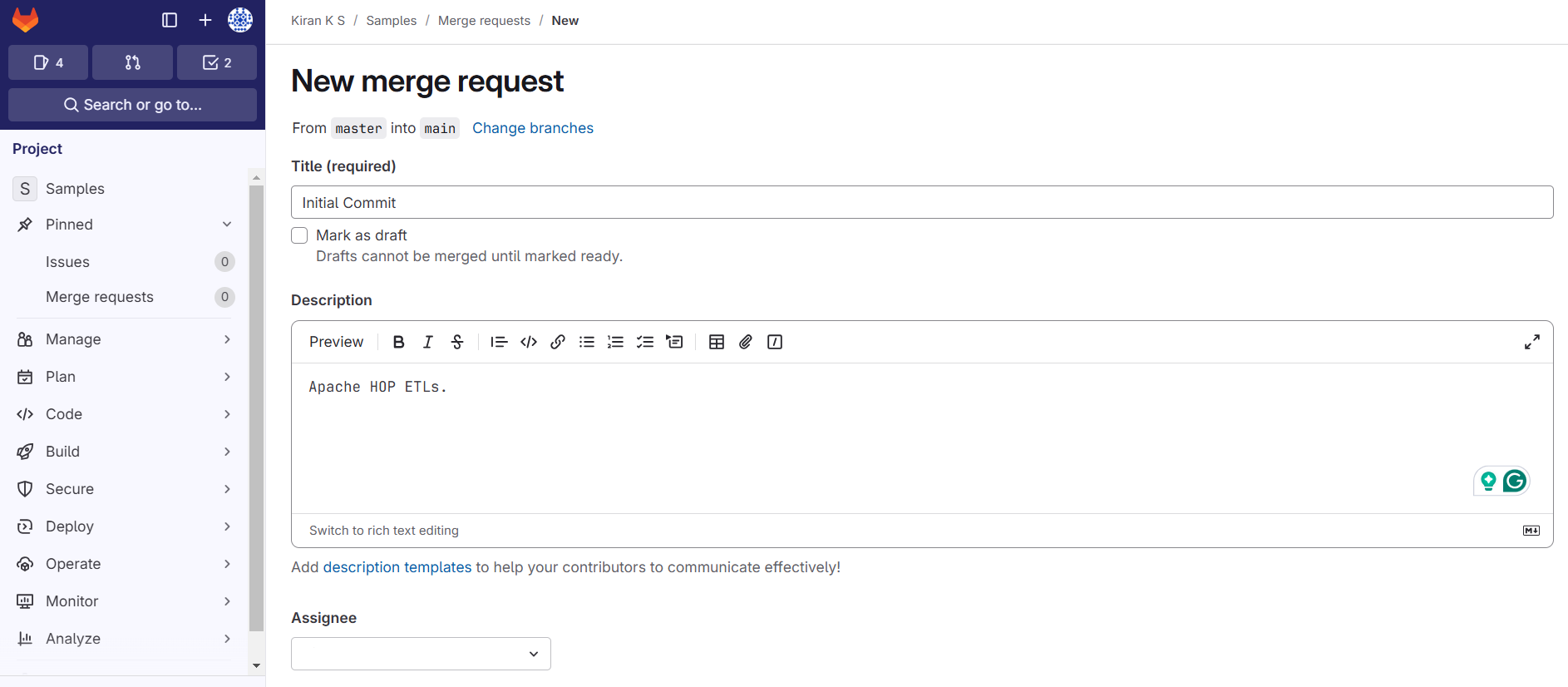
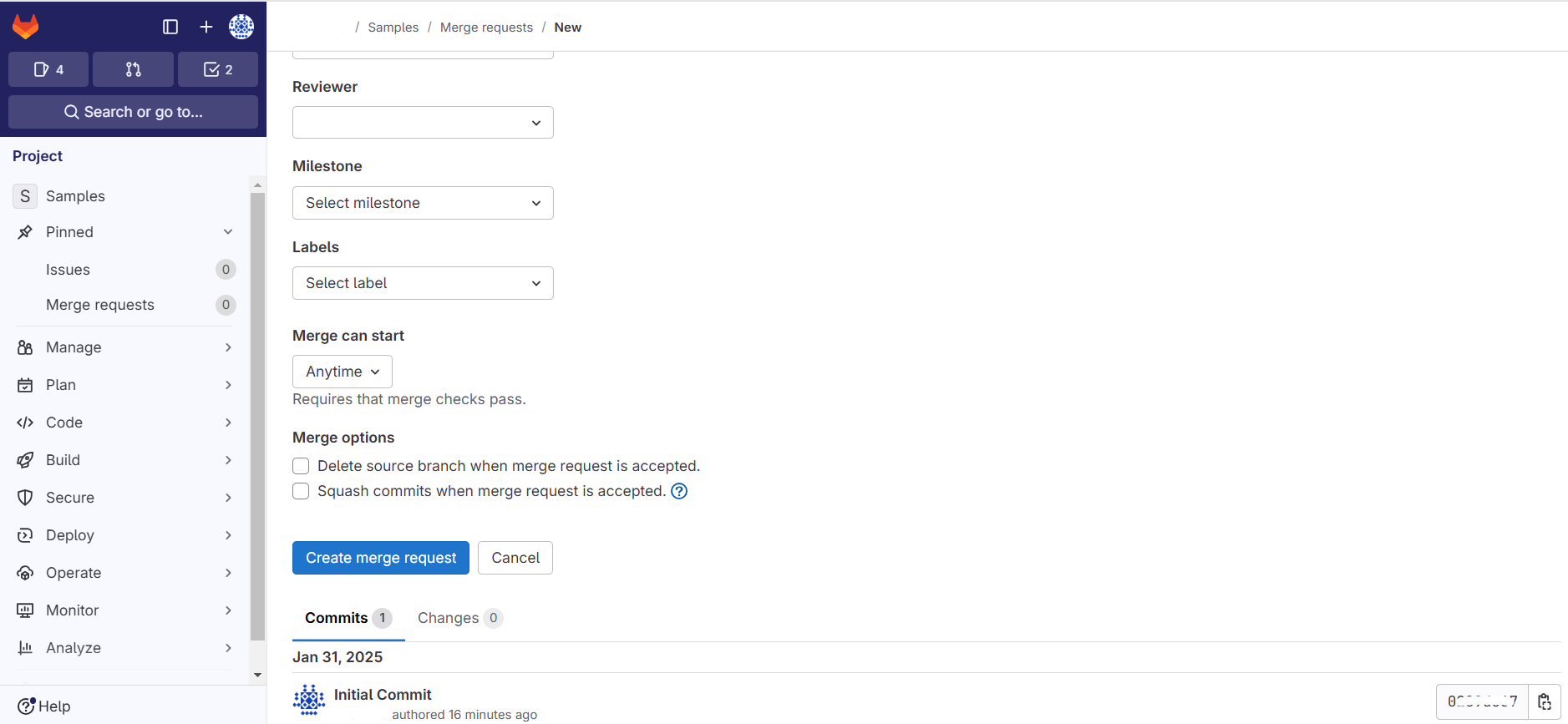
3. After the merge request is sent, the corresponding user should review the code artifacts to Approve and Merge the request.
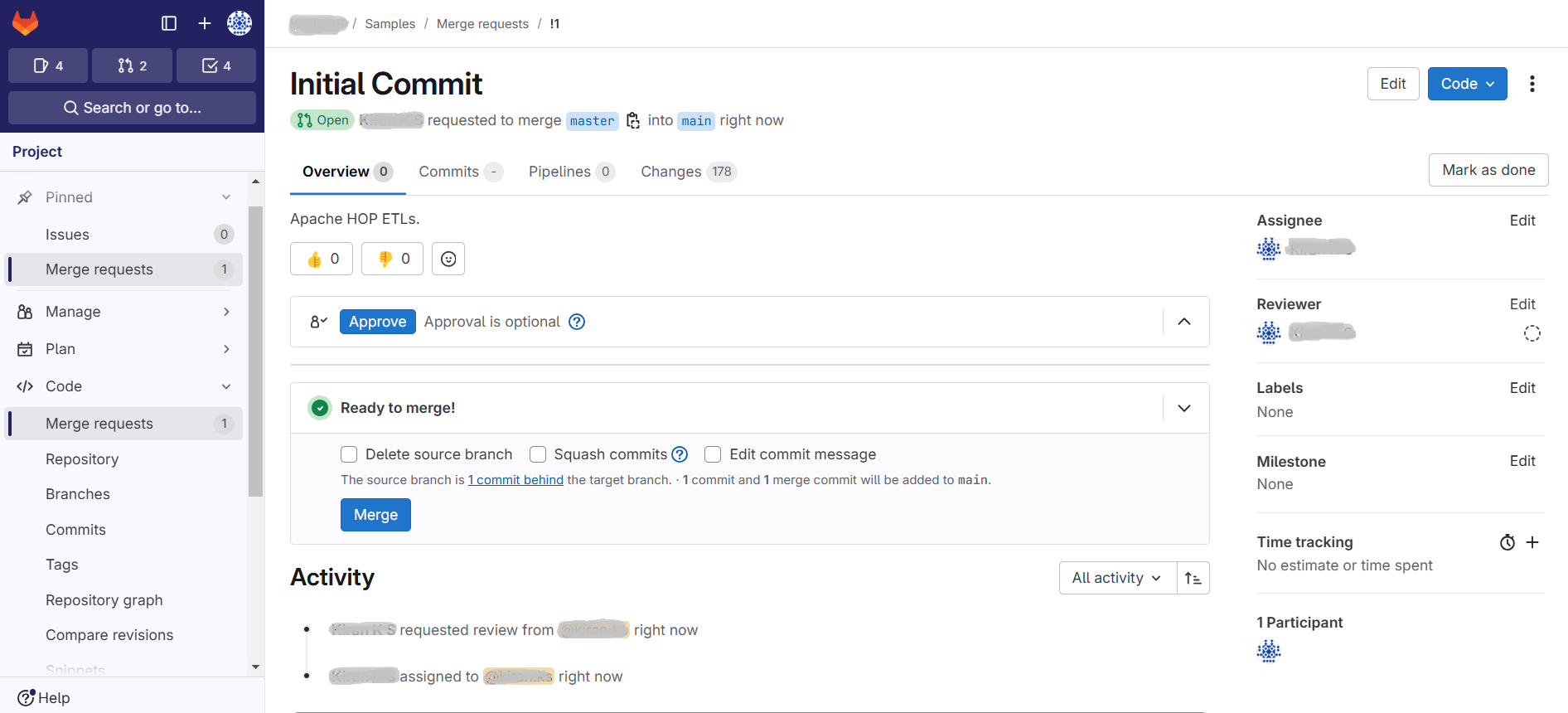
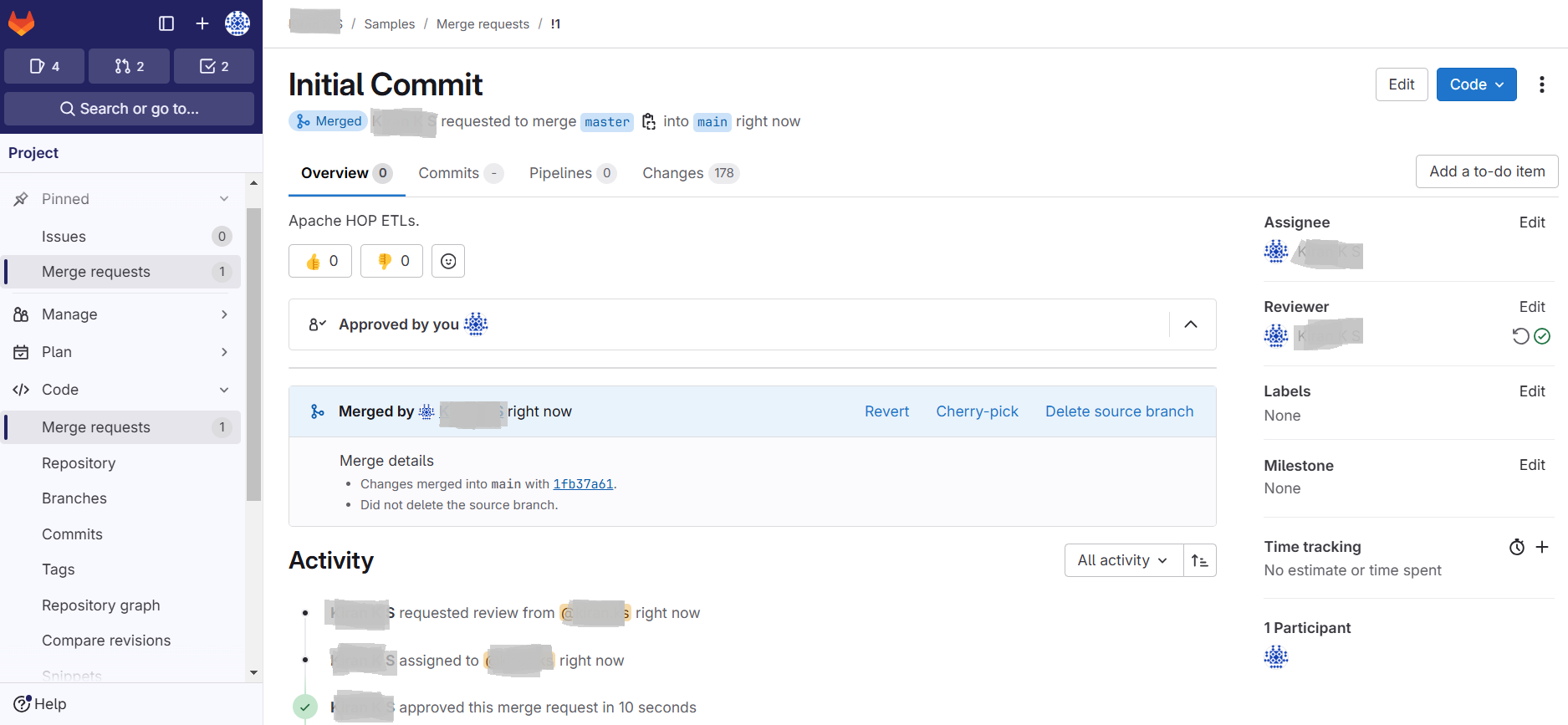
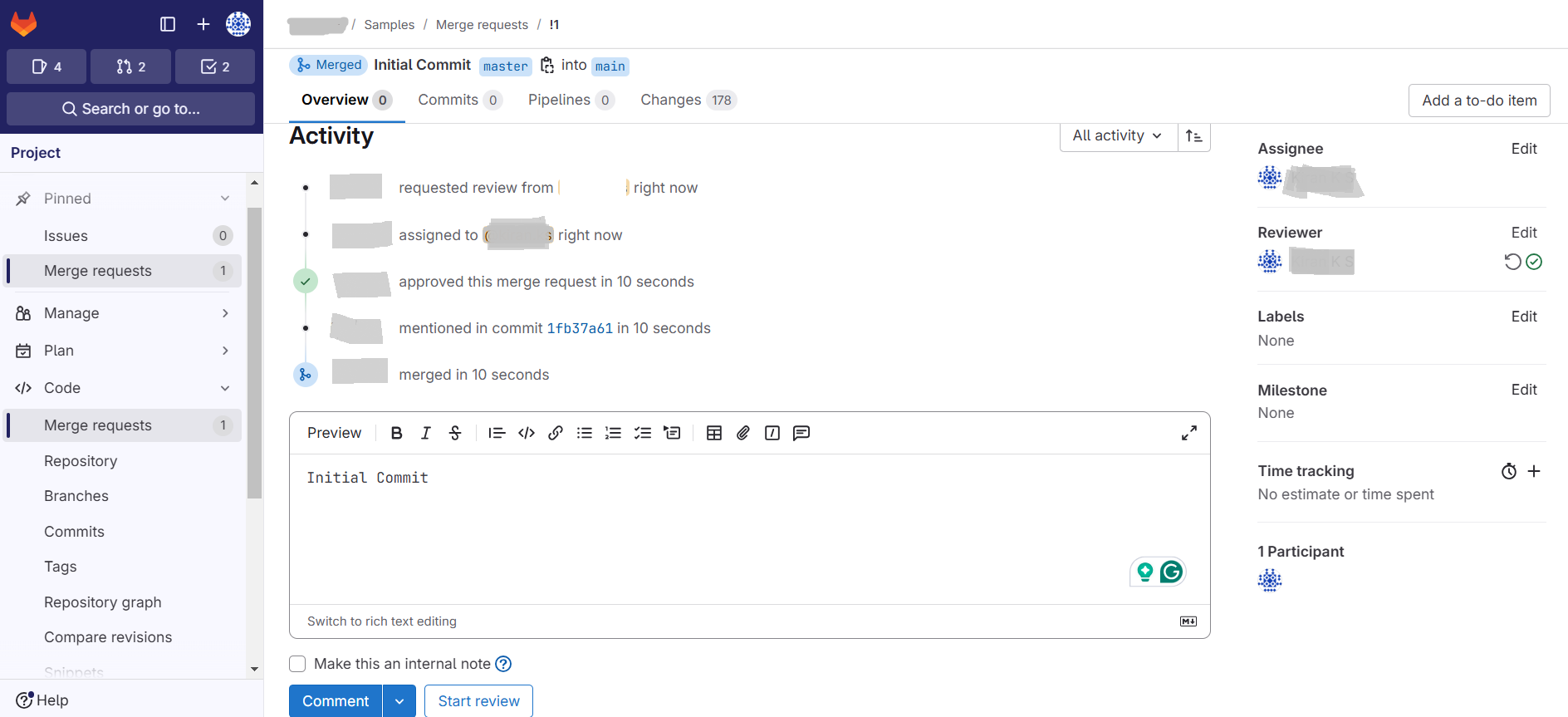
4. After the merge request is approved we should be able to see the merged artifacts in the GitLab project as shown in the screenshot below:
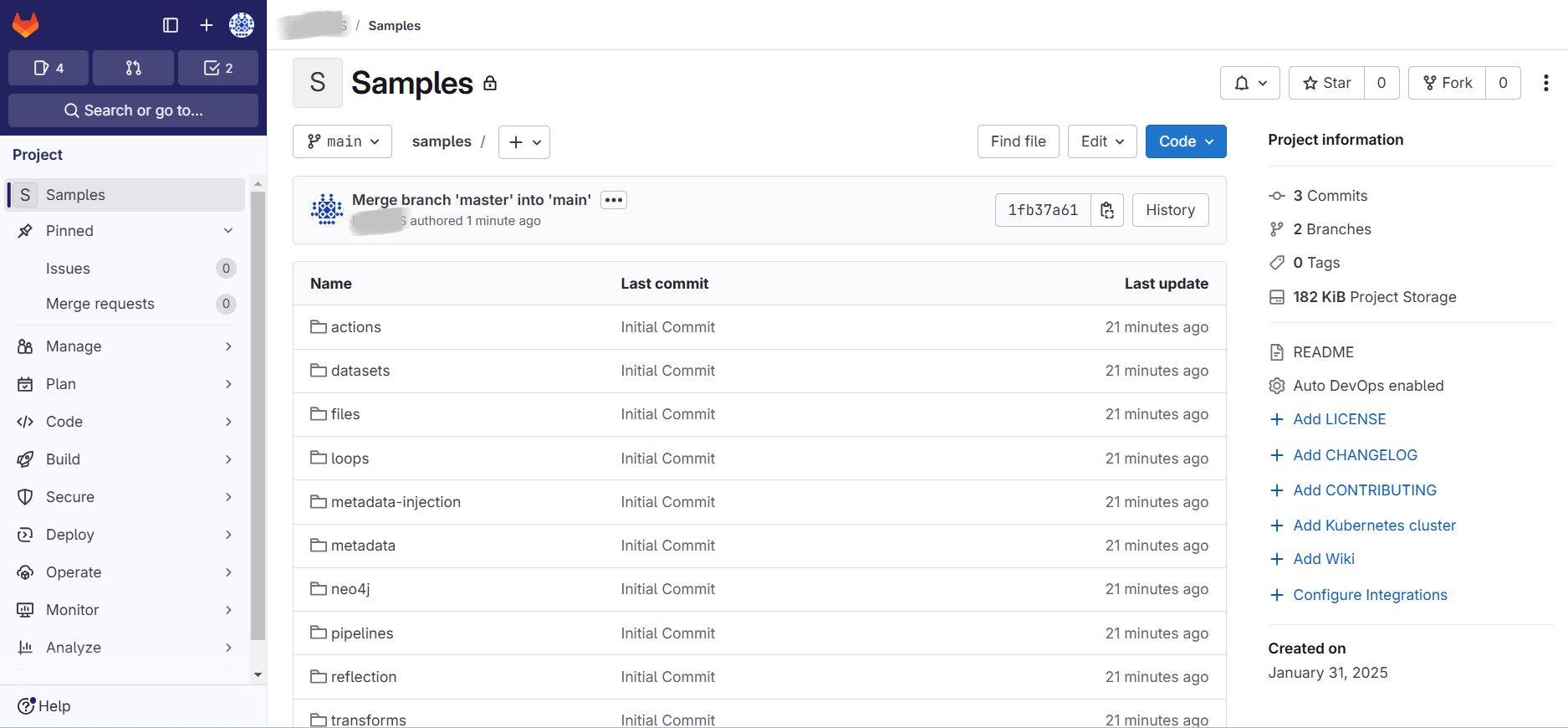
Note: Save Pipelines and Workflows:
- Store your Hop .hpl (pipelines) and .hwf (workflows) files in the Git repository.
- Use this folder as your main project path.
In the upcoming blogs, we will see how to streamline the Git operations (approval and merging) and deploy the merged development files to new environments (Dev->QA->Production) using Jenkins to implement more robust CICD operations. Stay tuned for the upcoming blog releases.
Best Practices for Git in Apache Hop
Apache Hop (Hop Orchestration Platform) provides seamless integration with Git, enabling version control for pipelines and workflows. This integration allows teams to collaborate effectively, track changes, and manage multiple versions of ETL processes.
- Use Descriptive Commit Messages
- Ensure commit messages clearly describe the changes made.
- Example: “Added error handling to data ingestion pipeline.”
- Commit Frequently
- Break changes into small, logical units and commit regularly.
- Leverage Branching
- Use branches for new features, bug fixes, or experimentation.
- Merge branches only after thorough testing.
- Collaborate Effectively
- Use pull requests to review and discuss changes with your team before merging.
- Keep the Repository Clean
- Use a .gitignore file to exclude temporary files and logs generated by Hop.
Conclusion
Using Git with Apache Hop GUI combines the power of modern version control with an intuitive data integration platform. By integrating Git into your ETL workflows, you’ll enhance collaboration and organization and improve your projects’ reliability and maintainability. Integrating GitLab CI with Apache HOP revolutionizes ETL workflow management by automating testing, deployment, and monitoring. This Continuous Integration (CI) ensures that data pipelines remain reliable, scalable, and maintainable in the ever-evolving landscape of data engineering. By embracing CI/CD best practices, organizations can enhance efficiency, reduce downtime, and accelerate the delivery of high-quality data insights.
Start leveraging Git actions in Apache Hop today to streamline your data orchestration projects.
Up Next
In the part of the CICD blog, we will talk more about Jenkins for the Continuous Deployment of the CI/CD process. Stay tuned.
Would you like us to officially set up Hop with GitLab & Jenkins CI/CD for your new project?
Official Links for Apache Hop and GitLab Integration
When writing this blog about Apache Hop and its integration with GitLab for CI/CD, the following were the official documentation and resources referred to. Below is a list of key official links:
1. Apache Hop Official Resources
- Apache Hop Official Website: https://hop.apache.org
- Apache Hop Documentation: https://hop.apache.org/docs/latest
- Apache Hop GitHub Repository: https://github.com/apache/hop
- Apache Hop Community & Discussions: https://hop.apache.org/community
2. GitLab CI/CD Official Resources
- GitLab Official Website: https://about.gitlab.com
- GitLab CI/CD Documentation: https://docs.gitlab.com/ee/ci/
- GitLab Runners (for automation): https://docs.gitlab.com/runner/
- GitLab API Reference: https://docs.gitlab.com/ee/api/
3. DevOps & CI/CD Best Practices
- Continuous Integration Overview: https://about.gitlab.com/stages-devops-lifecycle/continuous-integration/
- Continuous Deployment Best Practices: https://about.gitlab.com/stages-devops-lifecycle/continuous-deployment/
- Apache Hop with DevOps Pipelines: https://hop.apache.org/manual/latest/plugins/
These links will help you explore Apache Hop, GitLab, and CI/CD automation in more depth.
Other posts in the Apache HOP Blog Series
Check out our other Apache HOP Blog articles in the Series: