
Introduction
In our previous blog, Exploring Apache Druid: A High-Performance Real-Time Analytics Database, we discussed Apache Druid in more detail. In case you have missed it, it is recommended that you read it before continuing the Apache Druid blog series. In this blog, we talk about integrating Apache Superset and Apache Druid.
Apache Superset and Apache Druid are both open-source tools that are often used together in data analytics and business intelligence workflows. Here’s an overview of each and their relationship.
Apache Superset
Apache Superset is an open-source data exploration and visualization platform developed by Airbnb, it was later donated to the Apache Software Foundation. It is now a top-level Apache project, widely adopted across industries for data analytics and visualization.
- Type: Data visualization and exploration platform.
- Purpose: Enables users to create dashboards, charts, and reports for data analysis.
- Features:
- User-friendly interface for querying and visualizing data.
- Wide variety of visualization types (charts, maps, graphs, etc.).
- SQL Lab: A rich SQL IDE for writing and running queries.
- Extensible: Custom plugins and charts can be developed.
- Role-based access control and authentication options.
- Integrates with multiple data sources, including databases, warehouses, and big data engines.
- Use Cases:
- Business intelligence (BI) dashboards.
- Interactive data exploration.
- Monitoring and operational analytics.
Apache Druid
Apache Druid is a high-performance, distributed real-time analytics database designed to handle fast, interactive queries on large-scale datasets, especially those with a time component. It is widely used for powering business intelligence (BI) dashboards, real-time monitoring systems, and exploratory data analytics.
- Type: Real-time analytics database.
- Purpose: Designed for fast aggregation, ingestion, and querying of high-volume event streams.
- Features:
- Columnar storage format: Optimized for analytic workloads.
- Real-time ingestion: Can process and make data available immediately.
- Fast queries: High-performance query engine for OLAP (Online Analytical Processing).
- Scalability: Handles massive data volumes efficiently.
- Support for time-series data: Designed for datasets with a time component.
- Flexible data ingestion: Supports batch and streaming ingestion from sources like Kafka, Hadoop, and object stores.
- Use Cases:
- Real-time dashboards.
- Clickstream analytics.
- Operational intelligence and monitoring.
- Interactive drill-down analytics.
How They Work Together
- Integration: Superset can connect to Druid as a data source, enabling users to visualize and interact with the data stored in Druid.
- Workflow:
- Data Ingestion: Druid ingests large-scale data in real-time or batches from various sources.
- Data Querying: Superset uses Druid’s fast query capabilities to retrieve data for visualizations.
- Visualization: Superset presents the data in user-friendly dashboards, allowing users to explore and analyze it.
Key Advantages of Using Them Together
- Speed: Druid’s real-time and high-speed querying capabilities complement Superset’s visualization features, enabling near real-time analytics.
- Scalability: The combination is suitable for high-throughput environments where large-scale data analysis is needed.
- Flexibility: Supports a wide range of analytics use cases, from real-time monitoring to historical data analysis.
Use Cases of Apache Druid and Apache Superset
- Fraud Detection: Analyzing transactional data for anomalies.
- Real-Time Analytics: Monitoring website traffic, application performance, or IoT devices in real-time.
- Operational Intelligence: Tracking business metrics like revenue, sales, or customer behaviour.
- Clickstream Analysis: Analyzing user interactions and behaviour on websites and apps.
- Log and Event Analytics: Parsing and querying log files or event streams.
Importance of Integrating Apache Druid with Apache Superset
Integrating Apache Druid with Apache Superset opens quite a few doors for the organization to really address high-scale data analysis and interactive visualization needs. Here’s why this combination is so powerful:
- High-Performance Analytics:
Druid’s Speed: Apache Druid optimizes low-latency queries and fast aggregation and is designed with large datasets in mind. That can be huge because quick response means Superset can deliver good, reusable, production-quality representations.
Real-Time Data: Druid supports real-time data ingestion, allowing Superset dashboards to visualise near-live data streams, making it suitable for monitoring and operational analytics.
- Advanced Query Capabilities:
Complex Aggregations: Druid’s ability to handle complex OLAP-style aggregations and filtering ensures that Superset can provide rich and detailed visualizations.
Native Time-Series Support: Druid’s in-built time-series functionalities allow seamless integration for Superset’s time-series charts and analysis.
- Scalability:
Designed for Big Data: Druid is highly scalable and can manage billions of rows in an efficient manner. Together with Superset, it helps dashboards scale easily for high volumes of data.
Distributed Architecture: Being by nature distributed, Druid ensures reliable performance of Superset even when it’s under high loads or many concurrent user sessions.
- Simplified Data Exploration:
Columnar Storage: This columnar storage format on Druid greatly accelerates the exploratory data analysis of Superset since it supports scans of selected columns efficiently.
Pre-Aggregated Data: Superset can avail use from the roll-up and pre-aggregation mechanisms in Druid for reducing query cost as well as improving the visualization performance.
- Flawless Integration:
Incorporated Connector: Superset is natively integrated with Druid. Therefore, there would not be any hassle regarding implementing it. It lets users query Druid directly and curate dashboards using minimal configuration. Moreover, non-technical users can also perform SQL-like queries (Druid SQL) within the interface.
- Advanced Features:
Granular Access Control: When using Druid with Superset, it is possible to enforce row-level security and user-based data access, ensuring that sensitive data is only accessible to authorized users.
Segment-Level Optimization: Druid’s segment-based storage enables Superset to optimize queries for specific data slices.
- Cost Efficiency:
Efficient Resource Utilization: Druid’s architecture minimizes storage and compute costs while providing high-speed analytics, ensuring that Superset dashboards run efficiently.
- Real-Time Monitoring and BI:
Operational Dashboards: In the case of monitoring systems, website traffic, or application logs, Druid’s real-time capabilities make the dashboards built in Superset very effective for real-time operational intelligence.
Streaming Data Support: Druid supports ingesting stream-processing-enabled data sources; for example, Kafka’s ingestion is supported. This enables Superset to visualize live data with minimal delay.
Prerequisites
- The Superset Docker Container or instance should be up and running.
- Installation of pydruid in Superset Container or instance.
Installing PyDruid
1. Enable Druid-Specific SQL Queries
PyDruid is the Python library that serves as a client for Apache Druid. This allows Superset to:
- Run Druid SQL queries as efficiently as possible.
- Access Druid’s powerful querying capabilities directly from Superset’s SQL Lab and dashboards.
- Without this client, Superset will not be able to communicate with the Druid database, which consequently results in partial functionality or functionality at large
2. Native Connection Support
Superset is largely dependent upon PyDruid for:
- Seamless connections to Apache Druid.
- Translate Superset queries into Druid-native SQL or JSON that the Druid engine understands.
3. Efficient Data Fetching
PyDruid optimizes data fetching from Druid by
- Managing the query API of Druid in regards to aggregation, filtering, and time-series analysis
- Reducing latency due to better management of connections and responses
4. Advanced Visualization Features
Many features of advanced visualization available in Superset (like time-series charts and heat maps) depend on Druid’s capabilities, which PyDruid enables. It also exposes to Superset Druid’s granularity, time aggregation and access to complex metrics pre-aggregated in Druid.
5. Integration with Superset’s Druid Connector
The Druid connector in Superset relies on PyDruid as a dependency to:
- Register Druid as a data source.
- Allow Superset users the capability to query and visually explore Druid datasets directly.
- Without PyDruid the Druid connector in Superset will not work, limiting your ability to integrate Druid as a backend for analytics.
6. Data Discovery PyDruid Enables Superset to:
Fetch metadata from Druid, including schema, tables, and columns. Enable ad hoc exploration of Druid data in SQL Lab.
Apache Druid as a Data Source
- Make sure your Druid database application is set up and working fine in the respective ports.
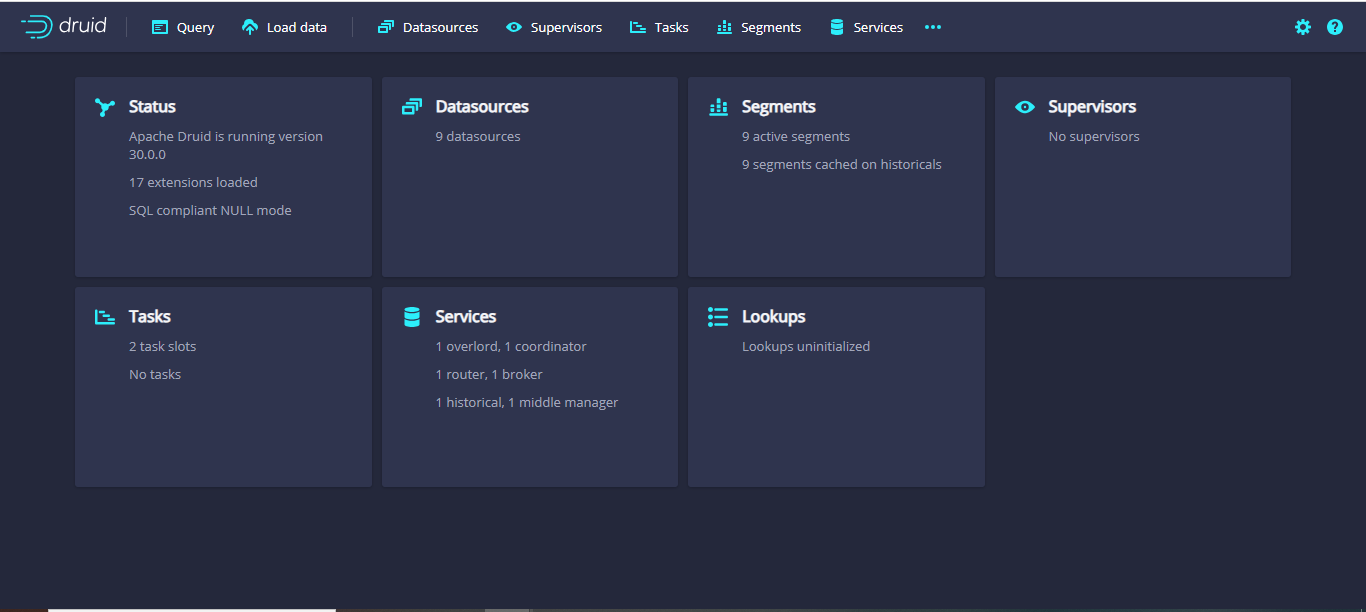
2. Install pydruid by logging into the container.
$ docker exec -it <superset_container_name> user=root /bin/bash
$ pip install pydruid
3. Once pydruid is installed, navigate to settings and click on database connections
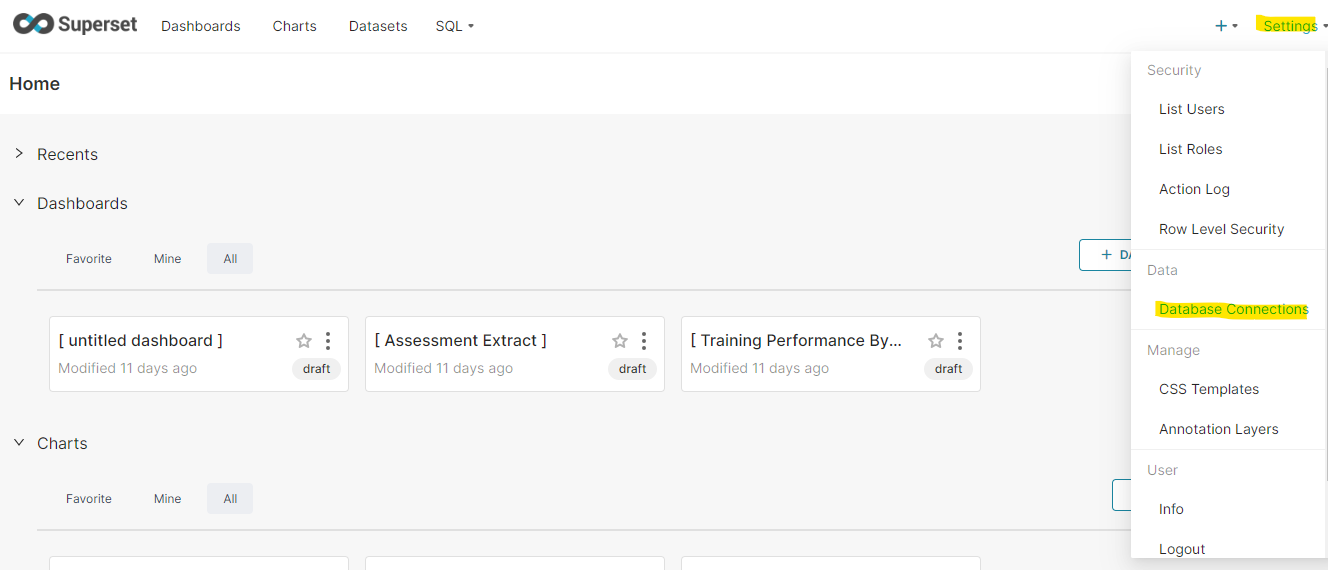
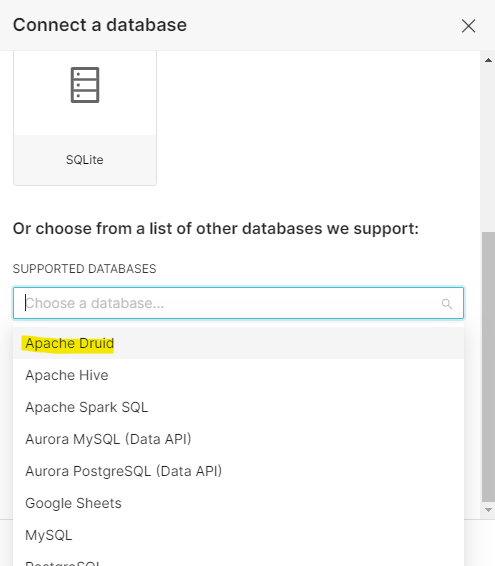
4. Click on Add Database and select Apache Druid as shown in the screenshot below:
5. Here we have to enter the SQLALCHEMY URI. To learn more about the SQLALCHEMY rules please follow the below link.
https://superset.apache.org/docs/configuration/databases/
6. For Druid the SQLALCHEMY URI will be in the below format:
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql

Note: druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql According to the Alchemy URI “<Port-default-9088>” the default ports will be “8888” or “8081”. If the druid you have installed is running on http without any secure connection the Alchemy URI with the above rule will work without any issue. Ex: druid://localhost:8888/druid/v2/sql/ If you have a secure connection normally druid://localhost:8888/druid/v2/sql/ will not work and provide an error. Here we will understand that we have to provide a domain name instead of localhost if we have enabled a secured connection for the druid UI. So we will make the changes and enter the URI as below druid://domain.name.com:8888/druid/v2/sql/. This will also not work. According to other sources we have to make the changes like druid+https://localhost:8888/druid/v2/sql/ OR druid+https://localhost:8888/druid/v2/sql/?ssl_verify=false Neither of them will work Normally once we enable a secured connection port HTTPS will be enabled to the site proxying the default ports of any of the other applications. So if we enter the below SQL ALCHEMY URI as below druid+https://domain.name.com:443/druid/v2/sql/?ssl=true Superset will understand that the druid is enabled with a secured connection and running in the HTTPS port. |
7. Since we have enabled the SSL to our druid application we have to enter the below SQLALCHEMY URI
druid+https://domain.name.com:443/druid/v2/sql/?ssl=true
and click on test connection.
8. Once we click on test connection the Apache superset will be integrated with the Apache druid and will be ready to be worked on.
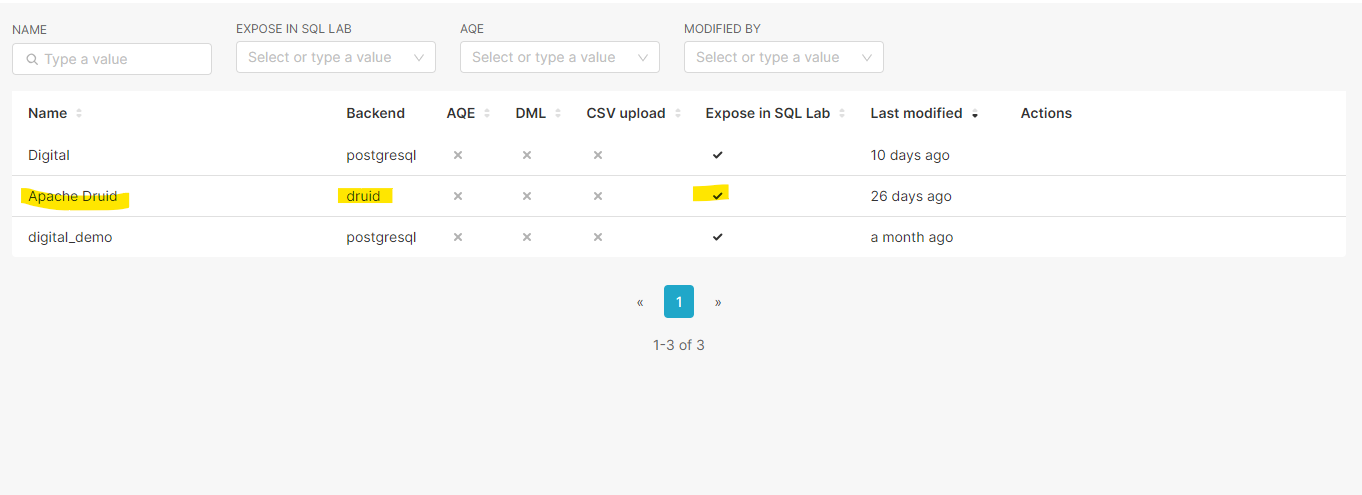
In the upcoming articles, we will talk about the data ingestion and visualization of Apache Druid data in the Apache Superset.
Apache Druid FAQ
1. What is Apache Druid used for?
Apache Druid is used for real-time analytics and fast querying of large-scale datasets. It’s particularly suitable for time-series data, clickstream analytics, operational intelligence, and real-time monitoring.
2. What are Druid’s ingestion methods?
Druid supports:
- Streaming ingestion: Data from Kafka, Kinesis, etc., is ingested in real-time.
- Batch ingestion: Data from Hadoop, S3, or other static sources is ingested in batches.
3. How does Druid achieve fast queries?
Druid uses:
- Columnar storage: Optimizes storage for analytic queries.
- Advanced indexing: Bitmap and inverted indexes speed up filtering and aggregation.
- Distributed architecture: Spreads query load across multiple nodes.
4. Can Druid handle transactional data (OLTP)?
No. Druid is optimized for OLAP (Online Analytical Processing) and is not suitable for transactional use cases.
5. How does Druid manage data storage?
- Data is segmented into immutable chunks and stored in Deep Storage (e.g., S3, HDFS).
- Historical nodes cache frequently accessed segments for faster querying.
6. What query languages does Druid support?
- SQL: Provides a familiar interface for querying.
- Native JSON-based query language: Offers more flexibility and advanced features.
7. What are the core components of Apache Druid?
- Broker: Routes queries to appropriate nodes.
- Historical nodes: Serve immutable data.
- MiddleManager: Handles ingestion tasks.
- Overlord: Coordinates ingestion processes.
- Coordinator: Manages data availability and balancing.
8. What integrations does Druid support?
Druid integrates with tools like:
- Apache Superset
- Tableau
- Grafana
- Stream ingestion tools (Kafka, Kinesis)
- Batch processing frameworks (Hadoop, Spark)
9. Is Apache Druid free to use?
Yes, it’s open-source and distributed under the Apache License 2.0.
10. What are some alternatives to Apache Druid?
Alternatives include:
- ClickHouse
- Elasticsearch
- BigQuery
- Snowflake
Apache Superset FAQ
1. What is Apache Superset?
Apache Superset is an open-source data visualization and exploration platform. It allows users to create dashboards, charts, and interactive visualizations from various data sources.
2. What types of visualizations does Superset support?
Superset offers:
- Line charts, bar charts, pie charts.
- Geographic visualizations like maps.
- Pivot tables, histograms, and heatmaps.
- Custom visualizations via plugins.
3. What data sources can Superset connect to?
Superset supports:
- Relational databases (PostgreSQL, MySQL, SQLite).
- Big data engines (Hive, Presto, Trino, BigQuery).
- Analytics databases (Apache Druid, ClickHouse).
4. Is Apache Superset a replacement for Tableau or Power BI?
Superset is a robust, open-source alternative to commercial BI tools. While it’s feature-rich, it may require more setup and development effort compared to proprietary solutions like Tableau.
5. What query languages does Superset support?
Superset primarily supports SQL for querying data. Its SQL Lab provides an environment for writing, testing, and running queries.
6. How does Superset handle user authentication?
Superset supports:
- Database-based login.
- OAuth, LDAP, OpenID Connect, and other SSO mechanisms.
- Role-based access control (RBAC) for managing permissions.
7. How do I install Superset?
Superset can be installed using:
- Docker: For containerized deployments.
- Python pip: For a native installation in a Python environment.
- Helm: For Kubernetes-based setups.
8. Can I use Superset with real-time data?
Yes. By integrating Superset with real-time analytics platforms like Apache Druid or streaming data sources, you can build dashboards that reflect live data.
9. What are Superset’s limitations?
- Requires knowledge of SQL for advanced queries.
- May not have the polish or advanced features of proprietary BI tools like Tableau.
- Customization and extensibility require some development effort.
10. How does Superset handle performance?
Superset performance depends on:
- The efficiency of the connected database or analytics engine.
- The complexity of queries and visualizations.
- Hardware resources and configuration.
Would you like further details on specific features or help setting up either tool? Reach out to us
Watch the Apache Blog Series
Stay tuned for the upcoming Apache Blog Series:
- Exploring Apache Druid: A High-Performance Real-Time Analytics Database
- Unlocking Data Insights with Apache Superset
- Streamlining Apache HOP Workflow Management with Apache Airflow
- Comparison of and Migrating from Pentaho Data Integration PDI/ Kettle to Apache HOP
- Why choose Apache Druid over Vertica
- Why choose Apache Druid over Snowflake
- Why choose Apache Druid over Google Big Query




